Elasticsearch入门
1. 什么是 Elasticsearch
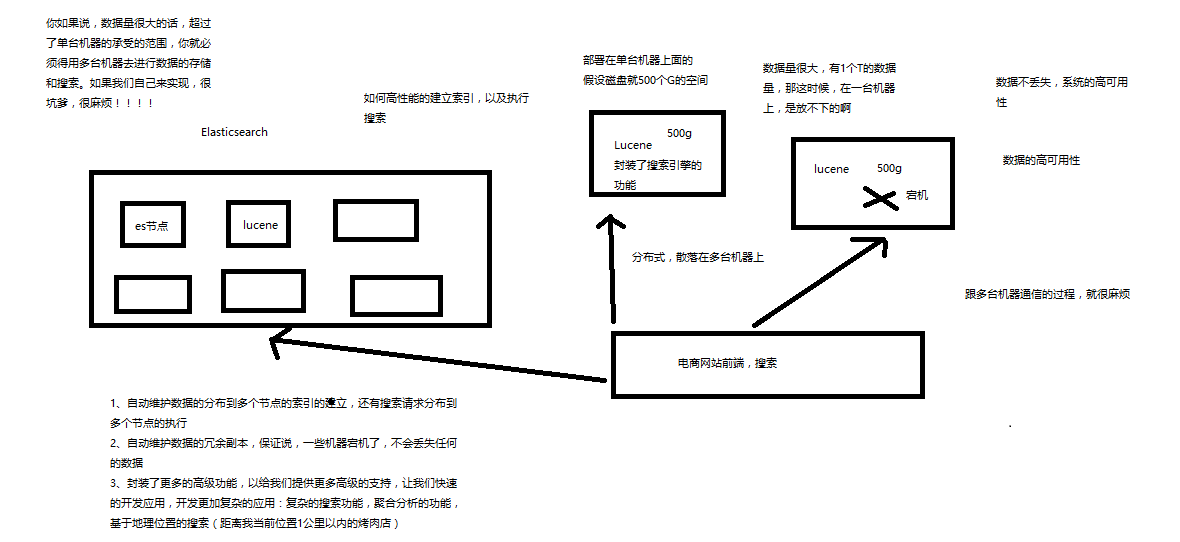
Elasticsearch,分布式,高性能,高可用,可伸缩的搜索和分析系统
1、什么是搜索?
2、如果用数据库做搜索会怎么样?
3、什么是全文检索、倒排索引和 Lucene?
4、什么是 Elasticsearch?
1.1 什么是搜索
百度:我们比如说想找寻任何的信息的时候,就会上百度去搜索一下,比如说找一部自己喜欢的电影,或者说找一本喜欢的书,或者找一条感兴趣的新闻(提到搜索的第一印象)
百度 != 搜索,这是不对的
垂直搜索(站内搜索)
互联网的搜索:电商网站,招聘网站,新闻网站,各种 app
IT 系统的搜索:OA 软件,办公自动化软件,会议管理,日程管理,项目管理,员工管理,搜索“张三”,“张三儿”,“张小三”;有个电商网站,卖家,后台管理系统,搜索“牙膏”,订单,“牙膏相关的订单”
搜索,就是在任何场景下,找寻你想要的信息,这个时候,会输入一段你要搜索的关键字,然后就期望找到这个关键字相关的有些信息
1.2 使用数据库做搜索会怎样
做软件开发的话,或者对 IT、计算机有一定的了解的话,都知道,数据都是存储在数据库里面的,比如说电商网站的商品信息,招聘网站的职位信息,新闻网站的新闻信息,等等吧。所以说,很自然的一点,如果说从技术的角度去考虑,如何实现如说,电商网站内部的搜索功能的话,就可以考虑,去使用数据库去进行搜索。
1、比方说,每条记录的指定字段的文本,可能会很长,比如说“商品描述”字段的长度,有长达数千个,甚至数万个字符,这个时候,每次都要对每条记录的所有文本进行扫描,懒判断说,你包不包含我指定的这个关键词(比如说“牙膏”)
2、还不能将搜索词拆分开来,尽可能去搜索更多的符合你的期望的结果,比如输入“生化机”,就搜索不出来“生化危机”

用数据库来实现搜索,是不太靠谱的。通常来说,性能会很差的。
1.3 什么是全文检索和 Lucene
(1)全文检索,倒排索引

(2)lucene,就是一个 jar 包,里面包含了封装好的各种建立倒排索引,以及进行搜索的代码,包括各种算法。我们就用 java 开发的时候,引入 lucene.jar,然后基于 lucene 的 api 进行去进行开发就可以了。用 lucene,我们就可以去将已有的数据建立索引,lucene 会在本地磁盘上面,给我们组织索引的数据结构。另外的话,我们也可以用 lucene 提供的一些功能和 api 来针对磁盘上额
1.4 什么是 Elasticsearch
2. 初始 Elasticsearch
2.1 Elasticsearch 的功能
2.1.1 分布式的搜索引擎和数据分析引擎
搜索:百度,网站的站内搜索,IT 系统的检索
数据分析:电商网站,最近 7 天牙膏这种商品销量排名前 10 的商家有哪些;新闻网站,最近 1 个月访问量排名前 3 的新闻版块是哪些
分布式,搜索,数据分析
2.1.2 全文检索,结构化检索,数据分析
全文检索:我想搜索商品名称包含牙膏的商品,select * from products where product_name like "%牙膏%"
结构化检索:我想搜索商品分类为日化用品的商品都有哪些,select * from products where category_id='日化用品'
部分匹配、自动完成、搜索纠错、搜索推荐
数据分析:我们分析每一个商品分类下有多少个商品,select category_id,count(*) from products group by category_id
2.13 对海量数据进行近实时的处理
分布式:ES 自动可以将海量数据分散到多台服务器上去存储和检索
海联数据的处理:分布式以后,就可以采用大量的服务器去存储和检索数据,自然而然就可以实现海量数据的处理了
近实时:检索个数据要花费 1 小时(这就不要近实时,离线批处理,batch-processing);在秒级别对数据进行搜索和分析
跟分布式/海量数据相反的:lucene,单机应用,只能在单台服务器上使用,最多只能处理单台服务器可以处理的数据量
2.2 Elasticsearch 的适用场景
- 维基百科,类似百度百科,牙膏,牙膏的维基百科,全文检索,高亮,搜索推荐
- The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
- Stack Overflow(国外的程序异常讨论论坛),IT 问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
- GitHub(开源代码管理),搜索上千亿行代码
- 电商网站,检索商品
- 日志数据分析,logstash 采集日志,ES 进行复杂的数据分析(ELK 技术,elasticsearch+logstash+kibana)
- 商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于 50 块钱,就通知我,我就去买
- BI 系统,商业智能,Business Intelligence。比如说有个大型商场集团,BI,分析一下某某区域最近 3 年的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表,xx 区,最近 3 年,每年消费金额呈现 100%的增长,而且用户群体 85%是高级白领,开一个新商场。ES 执行数据分析和挖掘,Kibana 进行数据可视化
- 国内:站内搜索(电商,招聘,门户,等等),IT 系统搜索(OA,CRM,ERP,等等),数据分析(ES 热门的一个使用场景)
2.3 Elasticsearch 的特点
- 可以作为一个大型分布式集群(数百台服务器)技术,处理 PB 级数据,服务大公司;也可以运行在单机上,服务小公司
- Elasticsearch 不是什么新技术,主要是将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的 ES;lucene(全文检索),商用的数据分析软件(也是有的),分布式数据库(mycat)
- 对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接 3 分钟部署一下 ES,就可以作为生产环境的系统来使用了,数据量不大,操作不是太复杂
- 数据库的功能面对很多领域是不够用的(事务,还有各种联机事务型的操作);特殊的功能,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;Elasticsearch 作为传统数据库的一个补充,提供了数据库所不不能提供的很多功能
3. Elasticsearch 核心概念
3.1 lucene 和 elasticsearch 的前世今生
lucene,最先进、功能最强大的搜索库,直接基于 lucene 开发,非常复杂,api 复杂(实现一些简单的功能,写大量的 java 代码),需要深入理解原理(各种索引结构)
elasticsearch,基于 lucene,隐藏复杂性,提供简单易用的 restful api 接口、java api 接口(还有其他语言的 api 接口)
(1)分布式的文档存储引擎
(2)分布式的搜索引擎和分析引擎
(3)分布式,支持 PB 级数据
开箱即用,优秀的默认参数,不需要任何额外设置,完全开源
关于 elasticsearch 的一个传说,有一个程序员失业了,陪着自己老婆去英国伦敦学习厨师课程。程序员在失业期间想给老婆写一个菜谱搜索引擎,觉得 lucene 实在太复杂了,就开发了一个封装了 lucene 的开源项目,compass。后来程序员找到了工作,是做分布式的高性能项目的,觉得 compass 不够,就写了 elasticsearch,让 lucene 变成分布式的系统。
3.2 elasticsearch 的核心概念
Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概 1 秒);基于 es 执行搜索和分析可以达到秒级
Cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是 elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
Node:节点,集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个 elasticsearch 集群,当然一个节点也可以组成一个 elasticsearch 集群
Document&field:文档,es 中的最小数据单元,一个 document 可以是一条客户数据,一条商品分类数据,一条订单数据,通常用 JSON 数据结构表示,每个 index 下的 type 中,都可以去存储多个 document。一个 document 里面有多个 field,每个 field 就是一个数据字段。
// product document { "product_id": "1", "product_name": "高露洁牙膏", "product_desc": "高效美白", "category_id": "2", "category_name": "日化用品" }Index:索引,包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个 index 包含很多 document,一个 index 就代表了一类类似的或者相同的 document。比如说建立一个 product index,商品索引,里面可能就存放了所有的商品数据,所有的商品 document。
Type:类型,每个索引里都可以有一个或多个 type,type 是 index 中的一个逻辑数据分类,一个 type 下的 document,都有相同的 field,比如博客系统,有一个索引,可以定义用户数据 type,博客数据 type,评论数据 type。
商品 index,里面存放了所有的商品数据,商品 document
但是商品分很多种类,每个种类的 document 的 field 可能不太一样,比如说电器商品,可能还包含一些诸如售后时间范围这样的特殊 field;生鲜商品,还包含一些诸如生鲜保质期之类的特殊 field
type,日化商品 type,电器商品 type,生鲜商品 type日化商品 type:product_id,product_name,product_desc,category_id,category_name
电器商品 type:product_id,product_name,product_desc,category_id,category_name,service_period
生鲜商品 type:product_id,product_name,product_desc,category_id,category_name,eat_period// 每一个type里面,都会包含一堆document { "product_id": "2", "product_name": "长虹电视机", "product_desc": "4k高清", "category_id": "3", "category_name": "电器", "service_period": "1年" } { "product_id": "3", "product_name": "基围虾", "product_desc": "纯天然,冰岛产", "category_id": "4", "category_name": "生鲜", "eat_period": "7天" }shard:单台机器无法存储大量数据,es 可以将一个索引中的数据切分为多个 shard,分布在多台服务器上存储。有了 shard 就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个 shard 都是一个 lucene index。
replica:任何一个服务器随时可能故障或宕机,此时 shard 可能就会丢失,因此可以为每个 shard 创建多个 replica 副本。replica 可以在 shard 故障时提供备用服务,保证数据不丢失,多个 replica 还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认 5 个),replica shard(随时修改数量,默认 1 个),默认每个索引 10 个 shard,5 个 primary shard,5 个 replica shard,最小的高可用配置,是 2 台服务器。

3.3 Elasticsearch vs MySQL
| MySQL | ElasticSearch |
|---|---|
| Database(数据库) | Index(索引) |
| Table(表) | Type(类型) |
| Row(行) | Document(文档) |
| Column(列) | Field(属性) |
| Schema | Mapping |
| Index | Everything is indexed |
| SQL | Query DSL |
| select * from … | GET http://… |
| update table set … | POST http://… |
| insert into table ... | PUT http://... |
4. Elasticsearch 安装
安装 JDK,至少 1.8.0_73 以上版本,java -version
下载和解压缩 Elasticsearch 安装包,目录结构
启动 Elasticsearch:bin\elasticsearch.bat,es 本身特点之一就是开箱即用,如果是中小型应用,数据量少,操作不是很复杂,直接启动就可以用了
检查 ES 是否启动成功:http://localhost:9200/?pretty
// name: node名称 // cluster_name: 集群名称(默认的集群名称就是elasticsearch) // version.number: 5.2.0,es版本号 { "name": "4onsTYV", "cluster_name": "elasticsearch", "cluster_uuid": "nKZ9VK_vQdSQ1J0Dx9gx1Q", "version": { "number": "5.2.0", "build_hash": "24e05b9", "build_date": "2017-01-24T19:52:35.800Z", "build_snapshot": false, "lucene_version": "6.4.0" }, "tagline": "You Know, for Search" }修改集群名称:elasticsearch.yml
下载和解压缩 Kibana 安装包,使用里面的开发界面,去操作 elasticsearch,作为我们学习 es 知识点的一个主要的界面入口
启动 Kibana:bin\kibana.bat
进入 Dev Tools 界面
GET _cluster/health
5. Elasticsearch 基本操作
5.1 document 数据格式
面向文档的搜索分析引擎
- 应用系统的数据结构都是面向对象的,复杂的
- 对象数据存储到数据库中,只能拆解开来,变为扁平的多张表,每次查询的时候还得还原回对象格式,相当麻烦
- ES 是面向文档的,文档中存储的数据结构,与面向对象的数据结构是一样的,基于这种文档数据结构,es 可以提供复杂的索引,全文检索,分析聚合等功能
- es 的 document 用 json 数据格式来表达
public class Employee {
private String email;
private String firstName;
private String lastName;
private EmployeeInfo info;
private Date joinDate;
}
private class EmployeeInfo {
private String bio; // 性格
private Integer age;
private String[] interests; // 兴趣爱好
}
EmployeeInfo info = new EmployeeInfo();
info.setBio("curious and modest");
info.setAge(30);
info.setInterests(new String[]{"bike", "climb"});
Employee employee = new Employee();
employee.setEmail("zhangsan@sina.com");
employee.setFirstName("san");
employee.setLastName("zhang");
employee.setInfo(info);
employee.setJoinDate(new Date());
employee 对象:里面包含了 Employee 类自己的属性,还有一个 EmployeeInfo 对象
两张表:employee 表,employee_info 表,将 employee 对象的数据重新拆开来,变成 Employee 数据和 EmployeeInfo 数据
employee 表:email,first_name,last_name,join_date,4 个字段
employee_info 表:bio,age,interests,3 个字段;此外还有一个外键字段,比如 employee_id,关联着 employee 表
{
"email": "zhangsan@sina.com",
"first_name": "san",
"last_name": "zhang",
"info": {
"bio": "curious and modest",
"age": 30,
"interests": ["bike", "climb"]
},
"join_date": "2017/01/01"
}
我们就明白了 es 的 document 数据格式和数据库的关系型数据格式的区别
5.2 电商网站商品管理案例背景介绍
有一个电商网站,需要为其基于 ES 构建一个后台系统,提供以下功能:
- 对商品信息进行 CRUD(增删改查)操作
- 执行简单的结构化查询
- 可以执行简单的全文检索,以及复杂的 phrase(短语)检索
- 对于全文检索的结果,可以进行高亮显示
- 对数据进行简单的聚合分析
5.3 简单的集群管理
5.3.1 检查集群的健康状况
es 提供了一套 api,叫做 cat api,可以查看 es 中各种各样的数据
GET /_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1488006741 15:12:21 elasticsearch yellow 1 1 1 1 0 0 1 0 - 50.0%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1488007113 15:18:33 elasticsearch green 2 2 2 1 0 0 0 0 - 100.0%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1488007216 15:20:16 elasticsearch yellow 1 1 1 1 0 0 1 0 - 50.0%
如何快速了解集群的健康状况?green、yellow、red?
- green:每个索引的 primary shard 和 replica shard 都是 active 状态的
- yellow:每个索引的 primary shard 都是 active 状态的,但是部分 replica shard 不是 active 状态,处于不可用的状态
- red:不是所有索引的 primary shard 都是 active 状态的,部分索引有数据丢失了
为什么现在会处于一个 yellow 状态?
我们现在就一个笔记本电脑,就启动了一个 es 进程,相当于就只有一个 node。现在 es 中有一个 index,就是 kibana 自己内置建立的 index。由于默认的配置是给每个 index 分配 5 个 primary shard 和 5 个 replica shard,而且 primary shard 和 replica shard 不能在同一台机器上(为了容错)。现在 kibana 自己建立的 index 是 1 个 primary shard 和 1 个 replica shard。当前就一个 node,所以只有 1 个 primary shard 被分配了和启动了,但是一个 replica shard 没有第二台机器去启动。
做一个小实验:此时只要启动第二个 es 进程,就会在 es 集群中有 2 个 node,然后那 1 个 replica shard 就会自动分配过去,然后 cluster status 就会变成 green 状态。
5.3.2 查看集群中有哪些索引
GET /_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open .kibana rUm9n9wMRQCCrRDEhqneBg 1 1 1 0 3.1kb 3.1kb
5.3.3 简单的索引操作
5.3.3.1 创建索引
PUT /test_index?pretty
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "test_index"
}
5.3.3.2 删除索引
DELETE /test_index?pretty
{
"acknowledged": true
}
5.4 商品的 CRUD 操作
5.4.1 新增文档,建立索引
新增商品:新增文档,建立索引
// PUT /index/type/id
// {
// "json数据"
// }
PUT /ecommerce/product/1
{
"name" : "gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
PUT /ecommerce/product/2
{
"name" : "jiajieshi yagao",
"desc" : "youxiao fangzhu",
"price" : 25,
"producer" : "jiajieshi producer",
"tags": [ "fangzhu" ]
}
PUT /ecommerce/product/3
{
"name" : "zhonghua yagao",
"desc" : "caoben zhiwu",
"price" : 40,
"producer" : "zhonghua producer",
"tags": [ "qingxin" ]
}
es 会自动建立 index 和 type,不需要提前创建,而且 es 默认会对 document 每个 field 都建立倒排索引,让其可以被搜索
5.4.2 查询商品:检索文档
## GET /index/type/id
GET /ecommerce/product/1
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"name": "gaolujie yagao",
"desc": "gaoxiao meibai",
"price": 30,
"producer": "gaolujie producer",
"tags": ["meibai", "fangzhu"]
}
}
5.4.3 修改商品:替换文档
PUT /ecommerce/product/1
{
"name" : "jiaqiangban gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
PUT /ecommerce/product/1
{
"name" : "jiaqiangban gaolujie yagao"
}
替换方式有一个不好,即使必须带上所有的 field,才能去进行信息的修改
5.4.4 修改商品:更新文档
POST /ecommerce/product/1/_update
{
"doc": {
"name": "jiaqiangban gaolujie yagao"
}
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 8,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
我的风格,其实有选择的情况下,不太喜欢念 ppt,或者照着文档做,或者直接粘贴写好的代码,尽量是纯手敲代码
5.4.5 删除商品:删除文档
DELETE /ecommerce/product/1
{
"found": true,
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 9,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"found": false
}
6. Elasticsearch 复杂查询
6.1 query string search
搜索全部商品:
GET /ecommerce/product/_search
- took:耗费了几毫秒
- timed_out:是否超时,这里是没有
- _shards:数据拆成了 5 个分片,所以对于搜索请求,会打到所有的 primary shard(或者是它的某个 replica shard 也可以)
- hits.total:查询结果的数量,3 个 document
- hits.max_score:score 的含义,就是 document 对于一个 search 的相关度的匹配分数,越相关,就越匹配,分数也高
- hits.hits:包含了匹配搜索的 document 的详细数据
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "ecommerce",
"_type": "product",
"_id": "2",
"_score": 1,
"_source": {
"name": "jiajieshi yagao",
"desc": "youxiao fangzhu",
"price": 25,
"producer": "jiajieshi producer",
"tags": ["fangzhu"]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_score": 1,
"_source": {
"name": "gaolujie yagao",
"desc": "gaoxiao meibai",
"price": 30,
"producer": "gaolujie producer",
"tags": ["meibai", "fangzhu"]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "3",
"_score": 1,
"_source": {
"name": "zhonghua yagao",
"desc": "caoben zhiwu",
"price": 40,
"producer": "zhonghua producer",
"tags": ["qingxin"]
}
}
]
}
}
query string search 的由来,因为 search 参数都是以 http 请求的 query string 来附带的
搜索商品名称中包含 yagao 的商品,而且按照售价降序排序:
GET /ecommerce/product/_search?q=name:yagao&sort=price:desc
适用于临时的在命令行使用一些工具,比如 curl,快速的发出请求,来检索想要的信息;但是如果查询请求很复杂,是很难去构建的
在生产环境中,几乎很少使用 query string search
6.2 query DSL
DSL:Domain Specified Language,特定领域的语言
http request body:请求体,可以用 json 的格式来构建查询语法,比较方便,可以构建各种复杂的语法,比 query string search 肯定强大多了
查询所有的商品
GET /ecommerce/product/_search { "query": { "match_all": {} } }查询名称包含 yagao 的商品,同时按照价格降序排序
GET /ecommerce/product/_search { "query" : { "match" : { "name" : "yagao" } }, "sort": [ { "price": "desc" } ] }分页查询商品,总共 3 条商品,假设每页就显示 1 条商品,现在显示第 2 页,所以就查出来第 2 个商品
GET /ecommerce/product/_search { "query": { "match_all": {} }, "from": 1, "size": 1 }指定要查询出来商品的名称和价格就可以
GET /ecommerce/product/_search { "query": { "match_all": {} }, "_source": ["name", "price"] }更加适合生产环境的使用,可以构建复杂的查询
6.3 query filter
搜索商品名称包含 yagao,而且售价大于 25 元的商品
GET /ecommerce/product/_search
{
"query" : {
"bool" : {
"must" : {
"match" : {
"name" : "yagao"
}
},
"filter" : {
"range" : {
"price" : { "gt" : 25 }
}
}
}
}
}
6.4 full-text search(全文检索)
新增一条数据
PUT /ecommerce/product/1
{
"name" : "special yagao",
"desc" : "special meibai",
"price" : 50,
"producer" : "special yagao producer",
"tags": [ "meibai" ]
}
全文检索
GET /ecommerce/product/_search
{
"query" : {
"match" : {
// 查询包含 yagao、producer、yagao producer的内容,相关度为 max_score
"producer" : "yagao producer"
}
}
}
尽量,无论是学什么技术,比如说你当初学 java,学 linux,学 shell,学 javascript,学 hadoop。。。。一定自己动手,特别是手工敲各种命令和代码,切记切记,减少复制粘贴的操作。只有自己动手手工敲,学习效果才最好。
producer 这个字段,会先被拆解,建立倒排索引
special 4
yagao 4
producer 1,2,3,4
gaolujie 1
zhognhua 3
jiajieshi 2
yagao producer ---> yagao 和 producer
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 0.70293105,
"hits": [
{
"_index": "ecommerce",
"_type": "product",
"_id": "4",
"_score": 0.70293105,
"_source": {
"name": "special yagao",
"desc": "special meibai",
"price": 50,
"producer": "special yagao producer",
"tags": ["meibai"]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_score": 0.25811607,
"_source": {
"name": "gaolujie yagao",
"desc": "gaoxiao meibai",
"price": 30,
"producer": "gaolujie producer",
"tags": ["meibai", "fangzhu"]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "3",
"_score": 0.25811607,
"_source": {
"name": "zhonghua yagao",
"desc": "caoben zhiwu",
"price": 40,
"producer": "zhonghua producer",
"tags": ["qingxin"]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "2",
"_score": 0.1805489,
"_source": {
"name": "jiajieshi yagao",
"desc": "youxiao fangzhu",
"price": 25,
"producer": "jiajieshi producer",
"tags": ["fangzhu"]
}
}
]
}
}
6.5 phrase search(短语搜索)
跟全文检索相对应,相反,全文检索会将输入的搜索串拆解开来,去倒排索引里面去一一匹配,只要能匹配上任意一个拆解后的单词,就可以作为结果返回
phrase search,要求输入的搜索串,必须在指定的字段文本中,完全包含一模一样的,才可以算匹配,才能作为结果返回
GET /ecommerce/product/_search
{
"query" : {
"match_phrase" : {
"producer" : "yagao producer"
}
}
}
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.70293105,
"hits": [
{
"_index": "ecommerce",
"_type": "product",
"_id": "4",
"_score": 0.70293105,
"_source": {
"name": "special yagao",
"desc": "special meibai",
"price": 50,
"producer": "special yagao producer",
"tags": ["meibai"]
}
}
]
}
}
6.6 highlight search(高亮搜索)
GET /ecommerce/product/_search
{
"query" : {
"match" : {
"producer" : "producer"
}
},
"highlight": {
"fields" : {
"producer" : {}
}
}
}
7. Elasticsearch 聚合分析
7.1 分组聚合求数量
第一个分析需求:计算每个 tag 下的商品数量
GET /ecommerce/product/_search
{
"aggs": {
"group_by_tags": {
"terms": { "field": "tags" }
}
}
}
将文本 field 的 fielddata 属性设置为 true
// 针对 es 5.2.0版本
PUT /ecommerce/_mapping/product
{
"properties": {
"tags": {
"type": "text",
"fielddata": true
}
}
}
GET /ecommerce/product/_search
{
"size": 0,
"aggs": {
"all_tags": {
"terms": { "field": "tags" }
}
}
}
```http
```json
{
"took": 20,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "fangzhu",
"doc_count": 2
},
{
"key": "meibai",
"doc_count": 2
},
{
"key": "qingxin",
"doc_count": 1
}
]
}
}
}
7.2 先过滤后分组
第二个聚合分析的需求:对名称中包含 yagao 的商品,计算每个 tag 下的商品数量
GET /ecommerce/product/_search
{
"size": 0,
"query": {
"match": {
"name": "yagao"
}
},
"aggs": {
"all_tags": {
"terms": {
"field": "tags"
}
}
}
}
7.3 先分组再平均
第三个聚合分析的需求:先分组,再算每组的平均值,计算每个 tag 下的商品的平均价格
GET /ecommerce/product/_search
{
"size": 0,
"aggs" : {
"group_by_tags" : {
"terms" : { "field" : "tags" },
"aggs" : {
"avg_price" : {
"avg" : { "field" : "price" }
}
}
}
}
}
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "fangzhu",
"doc_count": 2,
"avg_price": {
"value": 27.5
}
},
{
"key": "meibai",
"doc_count": 2,
"avg_price": {
"value": 40
}
},
{
"key": "qingxin",
"doc_count": 1,
"avg_price": {
"value": 40
}
}
]
}
}
}
7.4 先平均再排序
第四个数据分析需求:计算每个 tag 下的商品的平均价格,并且按照平均价格降序排序
GET /ecommerce/product/_search
{
"size": 0,
"aggs" : {
"all_tags" : {
"terms" : { "field" : "tags", "order": { "avg_price": "desc" } },
"aggs" : {
"avg_price" : {
"avg" : { "field" : "price" }
}
}
}
}
}
我们现在全部都是用 es 的 restful api 在学习和讲解 es 的所欲知识点和功能点,但是没有使用一些编程语言去讲解(比如 java),原因有以下:
1、es 最重要的 api,让我们进行各种尝试、学习甚至在某些环境下进行使用的 api,就是 restful api。如果你学习不用 es restful api,比如我上来就用 java api 来讲 es,也是可以的,但是你根本就漏掉了 es 知识的一大块,你都不知道它最重要的 restful api 是怎么用的
2、讲知识点,用 es restful api,更加方便,快捷,不用每次都写大量的 java 代码,能加快讲课的效率和速度,更加易于同学们关注 es 本身的知识和功能的学习
3、我们通常会讲完 es 知识点后,开始详细讲解 java api,如何用 java api 执行各种操作
4、我们每个篇章都会搭配一个项目实战,项目实战是完全基于 java 去开发的真实项目和系统
7.5 多级分组再平均
第五个数据分析需求:按照指定的价格范围区间进行分组,然后在每组内再按照 tag 进行分组,最后再计算每组的平均价格
GET /ecommerce/product/_search
{
"size": 0,
"aggs": {
"group_by_price": {
"range": {
"field": "price",
"ranges": [
{
"from": 0,
"to": 20
},
{
"from": 20,
"to": 40
},
{
"from": 40,
"to": 50
}
]
},
"aggs": {
"group_by_tags": {
"terms": {
"field": "tags"
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}