nacos深入理解
长轮询的时间间隔
之前讲到了配置更新的整个原理及源码,我们知道客户端会有一个长轮询的任务去检查服务器端的配置是否发生了变化,如果发生了变更,那么客户端会拿到变更的 groupKey, 再根据 groupKey 去获取配置项的最新值更新到本地的缓存以及文件中,那么这种每次都靠客户端去请求,那请求的时间间隔设置多少合适呢?
如果间隔时间设置的太长的话有可能无法及时获取服务端的变更,如果间隔时间设置的太短的话,那么频繁的请求对于服务端来说无疑也是一种负担,所以最好的方式是客户端每隔一段长度适中的时间去服务端请求,而在这期间如果配置发生变更,服务端能够主动将变更后的结果推送给客户端,这样既能保证客户端能够实时感知到配置的变化,也降低了服务端的压力。 我们来看看 nacos 设置的间隔时间是多久
长轮询的概念
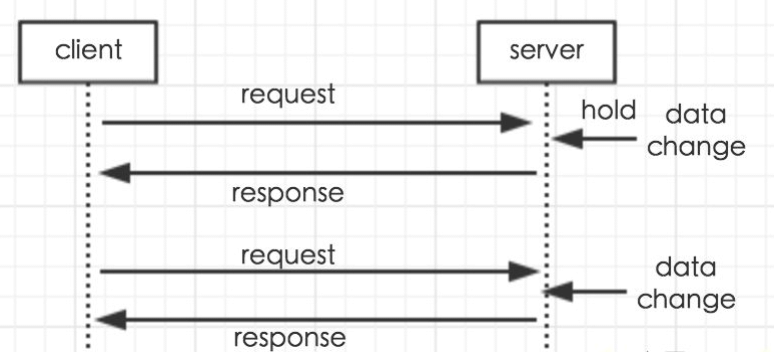
那么在讲解原理之前,先给大家解释一下什么叫长轮询
客户端发起一个请求到服务端,服务端收到客户端的请求后,并不会立刻响应给客户端,而是先把这个请求 hold住,然后服务端会在 hold 住的这段时间检查数据是否有更新,如果有,则响应给客户端,如果一直没有数据变更,则达到一定的时间(长轮询时间间隔)才返回。
长轮询典型的场景有: 扫码登录、扫码支付。
客户端长轮询
回到之前看的 nacos 源码,在ClientWorker 这个类里面,找到 checkUpdateConfigStr 这个方法,这里面就是去服务器端查询发生变化的 groupKey。
/**
* 从Server获取值变化了的DataID列表。返回的对象里只有dataId和group是有效的。 保证不返回NULL。
*/
List<String> checkUpdateConfigStr(String probeUpdateString, boolean isInitializingCacheList) throws IOException {
List<String> params = Arrays.asList(
Constants.PROBE_MODIFY_REQUEST, probeUpdateString);
List<String> headers = new ArrayList<String>(2);
headers.add("Long-Pulling-Timeout");
headers.add("" + timeout);
// told server do not hang me up if new initializing cacheData added in
if (isInitializingCacheList) {
headers.add("Long-Pulling-Timeout-No-Hangup");
headers.add("true");
}
if (StringUtils.isBlank(probeUpdateString)) {
return Collections.emptyList();
}
try {
HttpResult result = agent.httpPost(Constants.CONFIG_CONTROLLER_PATH + "/listener", headers, params, agent.getEncode(), timeout);
if (HttpURLConnection.HTTP_OK == result.code) {
setHealthServer(true);
return parseUpdateDataIdResponse(result.content);
} else {
setHealthServer(false);
LOGGER.error("[{}] [check-update] get changed dataId error, code: {}", agent.getName(), result.code);
}
} catch (IOException e) {
setHealthServer(false);
LOGGER.error("[" + agent.getName() + "] [check-update] get changed dataId exception", e);
throw e;
}
return Collections.emptyList();
}
这个方法最终会发起http请求,注意这里面有一个 timeout 的属性,
HttpResult result = agent.httpPost(Constants.CONFIG_CONTROLLER_PATH +
"/listener", headers, params, agent.getEncode(), timeout);
timeout 是在 init 这个方法中赋值的,默认情况下是30秒,可以通过 configLongPollTimeout 进行修改
private void init(Properties properties) {
timeout = Math.max(NumberUtils.toInt(
properties.getProperty(PropertyKeyConst.CONFIG_LONG_POLL_TIMEOUT),
Constants.CONFIG_LONG_POLL_TIMEOUT), Constants.MIN_CONFIG_LONG_POLL_TIMEOUT);
taskPenaltyTime = NumberUtils.toInt(
properties.getProperty(PropertyKeyConst.CONFIG_RETRY_TIME),
Constants.CONFIG_RETRY_TIME);
enableRemoteSyncConfig = Boolean.parseBoolean(
properties.getProperty(PropertyKeyConst.ENABLE_REMOTE_SYNC_CONFIG));
}
所以从这里得出的一个基本结论是
客户端发起一个轮询请求,超时时间是30s。 那么客户端为什么要等待30s才超时呢?不是越快越好吗?
客户端长轮询的时间间隔
我们可以在 nacos 的日志目录下 $NACOS_HOME/nacos/logs/config-client-request.log 文件
# 系统时间|超时时间(29.5s左右)|timeout|ip|poll
2019-08-25 15:26:23,689|29501|timeout|192.168.137.1|polling|1|55
2019-08-25 15:26:53,196|29501|timeout|192.168.137.1|polling|1|55
2019-08-25 15:27:22,701|29503|timeout|192.168.137.1|polling|1|55
2019-08-25 15:27:52,206|29502|timeout|192.168.137.1|polling|1|55
2019-08-25 15:28:21,710|29501|timeout|192.168.137.1|polling|1|55
2019-08-25 15:28:51,215|29502|timeout|192.168.137.1|polling|1|55
2019-08-25 15:29:20,719|29501|timeout|192.168.137.1|polling|1|55
可以看到一个现象,在配置没有发生变化的情况下,客户端会等29.5s以上,才请求到服务器端的结果。然后客户端拿到服务器端的结果之后,再做后续的操作。
如果在配置变更的情况下,由于客户端基于长轮询的连接保持,所以返回的时间会非常的短,我们可以做个小实验,在 nacos console中 频繁修改数据然后再观察一下
config-client-request.log 的变化
2019-08-25 15:18:59,968|29|null|192.168.137.1|get|example|DEFAULT_GROUP||d9030603cacd0b2deb1781e051401589|unknown
2019-08-25 15:19:09,059|0|nohangup|192.168.137.1|polling|1|55|0
2019-08-25 15:19:38,762|29503|timeout|192.168.137.1|polling|1|55
2019-08-25 15:20:08,268|29501|timeout|192.168.137.1|polling|1|55
2019-08-25 15:21:29,985|308|true|192.168.137.1|publish|example|DEFAULT_GROUP||b8094591196fcf009e8eb4d7b07847a1|null
2019-08-25 15:21:30,065|1|in-advance|192.168.137.1|polling|1|55|example+DEFAULT_GROUP

服务端的处理
分析完客户端之后,随着好奇心的驱使,服务端是如何处理客户端的请求的?那么同样,我们需要思考几个问题
- 客户端的长轮询响应时间受到哪些因素的影响
- 客户端的超时时间为什么要设置 30s
客户端发送的请求地址是: /v1/cs/configs/listener 找到服务端对应的方法
ConfigController
nacos是使用 spring mvc 提供的 rest api。这里面会调用 inner.doPollingConfig 进行处理
@RequestMapping(value = "/listener", method = RequestMethod.POST)
public void listener(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
request.setAttribute("org.apache.catalina.ASYNC_SUPPORTED", true);
String probeModify = request.getParameter("Listening-Configs");
if (StringUtils.isBlank(probeModify)) {
throw new IllegalArgumentException("invalid probeModify");
}
probeModify = URLDecoder.decode(probeModify, Constants.ENCODE);
Map<String, String> clientMd5Map;
try {
clientMd5Map = MD5Util.getClientMd5Map(probeModify);
} catch (Throwable e) {
throw new IllegalArgumentException("invalid probeModify");
}
// do long-polling
inner.doPollingConfig(request, response, clientMd5Map, probeModify.length());
}
doPollingConfig
这个方法中,兼容了长轮询和短轮询的逻辑,我们只需要关注长轮询的部分。再次进入到longPollingService.addLongPollingClient
public String doPollingConfig(HttpServletRequest request, HttpServletResponse
response,Map<String, String> clientMd5Map, int probeRequestSize)
throws IOException, ServletException {
// 长轮询
if (LongPollingService.isSupportLongPolling(request)) {
longPollingService.addLongPollingClient(request, response,
clientMd5Map, probeRequestSize);
return HttpServletResponse.SC_OK + "";
}
// else 兼容短轮询逻辑
List<String> changedGroups = MD5Util.compareMd5(request, response, clientMd5Map);
// 兼容短轮询result
String oldResult = MD5Util.compareMd5OldResult(changedGroups);
String newResult = MD5Util.compareMd5ResultString(changedGroups);
String version = request.getHeader(Constants.CLIENT_VERSION_HEADER);
if (version == null) {
version = "2.0.0";
}
int versionNum = Protocol.getVersionNumber(version);
/**
* 2.0.4版本以前, 返回值放入header中
*/
if (versionNum < START_LONGPOLLING_VERSION_NUM) {
response.addHeader(Constants.PROBE_MODIFY_RESPONSE, oldResult);
response.addHeader(Constants.PROBE_MODIFY_RESPONSE_NEW, newResult);
} else {
request.setAttribute("content", newResult);
}
// 禁用缓存
response.setHeader("Pragma", "no-cache");
response.setDateHeader("Expires", 0);
response.setHeader("Cache-Control", "no-cache,no-store");
response.setStatus(HttpServletResponse.SC_OK);
return HttpServletResponse.SC_OK + "";
}
longPollingService.addLongPollingClient
从方法名字上可以推测出,这个方法应该是把客户端的长轮询请求添加到某个任务中去。
- 获得客户端传递过来的超时时间,并且进行本地计算,提前 500ms 返回响应,这就能解释为什么客户端响应超时时间是29.5+了。当然如果 isFixedPolling=true 的情况下,不会提前返回响应
- 根据客户端请求过来的 md5 和服务器端对应的 group 下对应内容的 md5 进行比较,如果不一致,则通过generateResponse 将结果返回
- 如果配置文件没有发生变化,则通过 scheduler.execute 启动了一个定时任务,将客户端的长轮询请求封装成一个叫 ClientLongPolling 的任务,交给 scheduler 去执行
public void addLongPollingClient(HttpServletRequest req, HttpServletResponse rsp, Map<String, String> clientMd5Map,int probeRequestSize) {
//str表示超时时间,也就是timeout
String str = req.getHeader(LongPollingService.LONG_POLLING_HEADER);
String noHangUpFlag =
req.getHeader(LongPollingService.LONG_POLLING_NO_HANG_UP_HEADER);
String appName = req.getHeader(RequestUtil.CLIENT_APPNAME_HEADER);
String tag = req.getHeader("Vipserver-Tag");
int delayTime =
SwitchService.getSwitchInteger(SwitchService.FIXED_DELAY_TIME, 500);
/**
* 提前500ms返回响应,为避免客户端超时 @qiaoyi.dingqy 2013.10.22改动 add delay time for LoadBalance
*/
long timeout = Math.max(10000, Long.parseLong(str) - delayTime);
if (isFixedPolling()) {
timeout = Math.max(10000, getFixedPollingInterval());
// do nothing but set fix polling timeout
} else {
long start = System.currentTimeMillis();
List<String> changedGroups = MD5Util.compareMd5(req, rsp, clientMd5Map);
if (changedGroups.size() > 0) {
generateResponse(req, rsp, changedGroups);
LogUtil.clientLog.info("{}|{}|{}|{}|{}|{}|{}", System.currentTimeMillis() - start, "instant", RequestUtil.getRemoteIp(req), "polling", clientMd5Map.size(), probeRequestSize, changedGroups.size());
return;
} else if (noHangUpFlag != null && noHangUpFlag.equalsIgnoreCase(TRUE_STR)) {
LogUtil.clientLog.info("{}|{}|{}|{}|{}|{}|{}", System.currentTimeMillis() - start, "nohangup", RequestUtil.getRemoteIp(req), "polling", clientMd5Map.size(), probeRequestSize, changedGroups.size());
return;
}
}
String ip = RequestUtil.getRemoteIp(req);
// 一定要由HTTP线程调用,否则离开后容器会立即发送响应
final AsyncContext asyncContext = req.startAsync();
// AsyncContext.setTimeout()的超时时间不准,所以只能自己控制
asyncContext.setTimeout(0L);
scheduler.execute(new ClientLongPolling(asyncContext, clientMd5Map, ip,
probeRequestSize, timeout, appName, tag));
}
ClientLongPolling
接下来我们来分析一下,clientLongPolling 到底做了什么操作。或者说我们可以先猜测一下应该会做什么事情
- 这个任务要阻塞 29.5s 才能执行,因为立马执行没有任何意义,毕竟前面已经执行过一次了
- 如果在 29.5s+ 之内,数据发生变化,需要提前通知。需要有一种监控机制
基于这些猜想,我们可以看看它的实现过程
从代码粗粒度来看,它的实现似乎和我们的猜想一致,在run方法中,通过 scheduler.schedule 实现了一个定时任务,它的 delay 时间正好是前面计算的 29.5s。在这个任务中,会通过 MD5Util.compareMd5 来进行计算
那另外一个,当数据发生变化以后,肯定不能等到 29.5s 之后才通知呀,那怎么办呢?我们发现有一个 allSubs 的东西,它似乎和发布订阅有关系。那是不是有可能当前的 clientLongPolling 订阅了数据变化的事件呢?
public void run() {
asyncTimeoutFuture = scheduler.schedule(new Runnable() {
@Override
public void run() {
try {
getRetainIps().put(ClientLongPolling.this.ip, System.currentTimeMil1s());
/**
* 删除订阅关系
*/
allSubs.remove(ClientLongPolling.this);
if (isFixedPolling()) {
LogUtil.clientLog.info("{}|{}|{}|{}|{}|{}", (System.currentTimeMillis() - createTime), "fix", RequestUtil.getRemoteIp((
HttpServletRequest)asyncContext.getRequest()), "polling", clientMd5Map.size(), probeRequestSize);
List<String> changedGroups = MD5Util.compareMd5(
(HttpServletRequest)asyncContext.getRequest(),
(HttpServletResponse)asyncContext.getResponse(),
clientMd5Map);
if (changedGroups.size() > 0) {
sendResponse(changedGroups);
} else {
sendResponse(null);
}
} else {
LogUtil.clientLog.info("{}|{}|{}|{}|{}|{}", (System.currentTimeMillis() - createTime), "timeout", RequestUtil.getRemoteIp((
HttpServletRequest)asyncContext.getRequest()),"polling", clientMd5Map.size(), probeRequestSize);
sendResponse(null);
}
} catch (Throwable t) {
LogUtil.defaultLog.error("long polling error:" + t.getMessage(), t.getCause());
}
}
}, timeoutTime, TimeUnit.MILLISECONDS);
allSubs.add(this);
}
allSubs
allSubs 是一个队列,队列里面放了 ClientLongPolling 这个对象。这个队列似乎和配置变更有某种关联关系
/**
* 长轮询订阅关系
*/
final Queue<ClientLongPolling> allSubs;
allSubs.add(this);
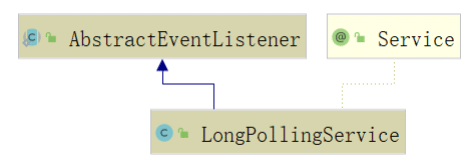
那这个时候,我的第一想法是,先去看一下当前这个类的类图,发现 LongPollingService 集成了AbstractEventListener,事件监听?果然没猜错。
AbstractEventListener
这里面有一个抽象的 onEvent 法,明显是用来处理事件的方法,而抽象方法必须由子类实现,所以意味着LongPollingService 里面肯定实现了 onEvent 方法
static public abstract class AbstractEventListener {
public AbstractEventListener() {
/**
* automatic register
*/
EventDispatcher.addEventListener(this);
}
/**
* 感兴趣的事件列表
*
* @return event list
*/
abstract public List<Class<? extends Event>> interest();
/**
* 处理事件
*
* @param event event
*/
abstract public void onEvent(Event event);
}
LongPollingService.onEvent
这个事件的实现方法中
- 判断事件类型是否为 LocalDataChangeEvent
- 通过 scheduler.execute 执行 DataChangeTask 这个任务
@Override
public void onEvent(Event event) {
if (isFixedPolling()) {
// ignore
} else {
if (event instanceof LocalDataChangeEvent) {
LocalDataChangeEvent evt = (LocalDataChangeEvent)event;
scheduler.execute(new DataChangeTask(evt.groupKey, evt.isBeta, evt.betaIps));
}
}
}
DataChangeTask.run
从名字可以看出来,这个是数据变化的任务,最让人兴奋的应该是,它里面有一个循环迭代器,从 allSubs 里面获得 ClientLongPolling
最后通过 clientSub.sendResponse 把数据返回到客户端。所以,这也就能够理解为何数据变化能够实时触发更新了。
public void run() {
try {
ConfigService.getContentBetaMd5(groupKey);
for (Iterator<ClientLongPolling> iter = allSubs.iterator(); iter.hasNext();) {
ClientLongPolling clientSub = iter.next();
if (clientSub.clientMd5Map.containsKey(groupKey)) {
// 如果beta发布且不在beta列表直接跳过
if (isBeta && !betaIps.contains(clientSub.ip)) {
continue;
}
// 如果tag发布且不在tag列表直接跳过
if (StringUtils.isNotBlank(tag) && !tag.equals(clientSub.tag)) {
continue;
}
getRetainIps().put(clientSub.ip, System.currentTimeMillis());
iter.remove(); // 删除订阅关系
LogUtil.clientLog.info("{}|{}|{}|{}|{}|{}|{}", (System.currentTimeMillis() - changeTime), "in-advance", RequestUtil.getRemoteIp((HttpServletRequest)clientSub.asyncContext.getRequest()), "polling", clientSub.clientMd5Map.size(), clientSub.probeRequestSize, groupKey);
clientSub.sendResponse(Arrays.asList(groupKey));
}
}
} catch (Throwable t) {
LogUtil.defaultLog.error("data change error:" + t.getMessage(), t.getCause());
}
}
那么接下来还有一个疑问是,数据变化之后是如何触发事件的呢? 所以我们定位到数据变化的请求类中,在ConfigController 这个类中,找到POST请求的方法
找到配置变更的位置, 发现数据持久化之后,会通过 EventDispatcher 进行事件发布 EventDispatcher.fireEvent 但是这个事件似乎不是我们所关心的事件,原因是这里发布的事件是 ConfigDataChangeEvent,而LongPollingService 感兴趣的事件是 LocalDataChangeEvent
@RequestMapping(method = RequestMethod.POST)
@ResponseBody
public Boolean publishConfig(...)
throws NacosException {
//省略部分代码
ConfigInfo configInfo = new ConfigInfo(dataId, group, tenant, appName, content);
if (StringUtils.isBlank(betaIps)) {
if (StringUtils.isBlank(tag)) {
persistService.insertOrUpdate(srcIp, srcUser, configInfo, time,
configAdvanceInfo, false);
EventDispatcher.fireEvent(new ConfigDataChangeEvent(
false,dataId, group, tenant, time.getTime()));
} else {
persistService.insertOrUpdateTag(configInfo, tag, srcIp,
srcUser, time, false);
EventDispatcher.fireEvent(new ConfigDataChangeEvent(
false, dataId, group, tenant, tag, time.getTime()));
}
} else { // beta publish
persistService.insertOrUpdateBeta(configInfo, betaIps, srcIp,
srcUser, time, false);
EventDispatcher.fireEvent(new ConfigDataChangeEvent(
true, dataId, group, tenant, time.getTime()));
}
ConfigTraceService.logPersistenceEvent(
dataId, group, tenant, requestIpApp, time.getTime(), LOCAL_IP,
ConfigTraceService.PERSISTENCE_EVENT_PUB, content);
return true;
}
后来我发现,在 Nacos 中有一个 DumpService,它会定时把变更后的数据 dump 到磁盘上,DumpService 在spring 启动之后,会调用 init 方法启动几个 dump 任务。然后在任务执行结束之后,会触发一个LocalDataChangeEvent 的事件
@PostConstruct
public void init() {
LogUtil.defaultLog.warn("DumpService start");
DumpProcessor processor = new DumpProcessor(this);
DumpAllProcessor dumpAllProcessor = new DumpAllProcessor(this);
DumpAllBetaProcessor dumpAllBetaProcessor = new DumpAllBetaProcessor(this);
DumpAllTagProcessor dumpAllTagProcessor = new DumpAllTagProcessor(this);
简单总结
简单总结一下刚刚分析的整个过程。
客户端发起长轮询请求
服务端收到请求以后,先比较服务端缓存中的数据是否相同,如果不同,则直接返回
如果相同,则通过 schedule 延迟 29.5s 之后再执行比较
为了保证当服务端在29.5s之内发生数据变化能够及时通知给客户端,服务端采用事件订阅的方式来监听服务端本地数据变化的事件,一旦收到事件,则触发 DataChangeTask 的通知,并且遍历 allStubs 队列中的ClientLongPolling,把结果写回到客户端,就完成了一次数据的推送
如果 DataChangeTask 任务完成了数据的 “推送” 之后,ClientLongPolling 中的调度任务又开始执行了怎么办呢?
很简单,只要在进行 “推送” 操作之前,先将原来等待执行的调度任务取消掉就可以了,这样就防止了推送操作写完响应数据之后,调度任务又去写响应数据,这时肯定会报错的。所以,在 ClientLongPolling 方法中,最开始的一个步骤就是删除订阅事件
所以总的来说,Nacos 采用推+拉的形式,来解决最开始关于长轮询时间间隔的问题。当然,30s 这个时间是可以设置的,而之所以定 30s,应该是一个经验值。
集群选举问题
Nacos支持集群模式,很显然。
而一旦涉及到集群,就涉及到主从,那么 nacos 是一种什么样的机制来实现的集群呢?
nacos 的集群类似于 zookeeper, 它分为 leader 角色和 follower 角色, 那么从这个角色的名字可以看出来,这个集群存在选举的机制。 因为如果自己不具备选举功能,角色的命名可能就是 master/slave了,当然这只是我基于这么多组件的命名的一个猜测
选举算法
Nacos集群采用 raft 算法来实现,它是相对 zookeeper 的选举算法较为简单的一种。
选举算法的核心在 RaftCore 中,包括数据的处理和数据同步
在Raft中,节点有三种角色:
- Leader:负责接收客户端的请求
- Candidate:用于选举Leader的一种角色
- Follower:负责响应来自Leader或者Candidate的请求
选举分为两个时间点
- 服务启动的时候
- leader 挂了的时候
所有节点启动的时候,都是 follower 状态。 如果在一段时间内如果没有收到 leader 的心跳(可能是没有 leader,也可能是 leader 挂了),那么 follower 会变成 Candidate。然后发起选举,选举之前,会增加 term,这个 term 和 zookeeper 中的 epoch 的道理是一样的。
- follower会投自己一票,并且给其他节点发送票据vote,等到其他节点回复
- 在这个过程中,可能出现几种情况
- 收到过半的票数通过,则成为leader
- 被告知其他节点已经成为 leader,则自己切换为 follower
- 一段时间内没有收到过半的投票,则重新发起选举
- 约束条件在任一term中,单个节点最多只能投一票
选举的几种情况
- 第一种情况,赢得选举之后,leader 会给所有节点发送消息,避免其他节点触发新的选举;
- 第二种情况,比如有三个节点A B C。A B 同时发起选举,而A的选举消息先到达C,C给A投了一票,当B的消息到达C时,已经不能满足上面提到的第一个约束,即C不会给B投票,而A和B显然都不会给对方投票。A胜出之后,会给B,C发心跳消息,节点B发现节点A的term不低于自己的term,知道有已经有Leader了,于是转换成 follower;
- 第三种情况, 没有任何节点获得 majority 投票,可能是平票的情况。假如总共有四个节点 (A/B/C/D),Node C、Node D 同时成为了candidate,但Node A投了NodeD一票,NodeB投了Node C一票,这就出现了平票 split vote 的情况。这个时候大家都在等啊等,直到超时后重新发起选举。如果出现平票的情况,那么就延长了系统不可用的时间,因此raft引入了 randomized election timeouts 来尽量避免平票情况
数据的处理
对于事务操作,请求会转发给 leader
非事务操作上,可以任意一个节点来处理
下面这段代码摘自 RaftCore , 在发布内容的时候,做了两个事情
- 如果当前的节点不是leader,则转发给leader节点处理
- 如果是,则向所有节点发送onPublish
nacos到这里就告一段落了,那么接下来了解一下另外一个 Sentinel,在了解Sentinel之前,我们先来聊一些场景
限流的基本认识
场景分析
一个互联网产品,打算搞一次大促来增加销量以及曝光。公司的架构师基于往期的流量情况做了一个活动流量的预估,然后整个公司的各个技术团队开始按照这个目标进行设计和优化,最终在大家不懈的努力之下,达到了链路压测的目标流量峰值。到了活动开始那天,大家都在盯着监控面板,看着流量像洪水一样涌进来。由于前期的宣传工作做得很好,使得这个流量远远超过预估的峰值,后端服务开始不稳定,CPU、内存各种爆表。部分服务开始出现无响应的情况。最后,整个系统开始崩溃,用户无法正常访问服务。最后导致公司巨大的损失。
引入限流
在 10.1 黄金周,各大旅游景点都是人满为患。所有有些景点为了避免出现踩踏事故,会采取限流措施。
那在架构场景中,是不是也能这么做呢?针对这个场景,能不能够设置一个最大的流量限制,如果超过这个流量,我们就拒绝提供服务,从而使得我们的服务不会挂掉。
当然,限流虽然能够保护系统不被压垮,但是对于被限流的用户,就会很不开心。所以限流其实是一种有损的解决方案。但是相比于全部不可用,有损服务是最好的一种解决办法
限流的作用
除了前面说的限流使用场景之外,限流的设计还能防止恶意请求流量、恶意攻击
所以,限流的基本原理是通过对并发访问/请求进行限速或者一个时间窗口内的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务(定向到错误页或者告知资源没有了)、排队或等待(秒杀、下单)、降级(返回兜底数据或默认数据或默认数据,如商品详情页库存默认有货)
一般互联网企业常见的限流有:限制总并发数(如数据库连接池、线程池)、限制瞬时并发数(nginx 的limit_conn模块,用来限制瞬时并发连接数)、限制时间窗口内的平均速率(如Guava的 RateLimiter、nginx的limit_req模块,限制每秒的平均速率);其他的还有限制远程接口调用速率、限制 MQ 的消费速率。另外还可以根据网络连接数、网络流量、CPU或内存负载等来限流。
有了限流,就意味着在处理高并发的时候多了一种保护机制,不用担心瞬间流量导致系统挂掉或雪崩,最终做到有损服务而不是不服务;但是限流需要评估好,不能乱用,否则一些正常流量出现一些奇怪的问题而导致用户体验很差造成用户流失。
常见的限流算法
滑动窗口
发送和接受方都会维护一个数据帧的序列,这个序列被称作窗口。发送方的窗口大小由接受方确定,目的在于控制发送速度,以免接受方的缓存不够大,而导致溢出,同时控制流量也可以避免网络拥塞。下面图中的4,5,6号数据帧已经被发送出去,但是未收到关联的 ACK,7,8,9 帧则是等待发送。可以看出发送端的窗口大小为 6,这是由接受端告知的。此时如果发送端收到4号ACK,则窗口的左边缘向右收缩,窗口的右边缘则向右扩展,此时窗口就向前“滑动了”,即数据帧10也可以被发送。

漏桶算法
控制传输速率 Leaky bucket
漏桶算法思路是,不断的往桶里面注水,无论注水的速度是大还是小,水都是按固定的速率往外漏水;如果桶满了,水会溢出;
桶本身具有一个恒定的速率往下漏水,而上方时快时慢的会有水进入桶内。当桶还未满时,上方的水可以加入。一旦水满,上方的水就无法加入。桶满正是算法中的一个关键的触发条件(即流量异常判断成立的条件)。而此条件下如何处理上方流下来的水,有两种方式
在桶满水之后,常见的两种处理方式为:
- 暂时拦截住上方水的向下流动,等待桶中的一部分水漏走后,再放行上方水。
- 溢出的上方水直接抛弃。
特点
- 漏水的速率是固定的
- 即使存在突然注水量变大的情况,漏水的速率也是固定的

令牌桶算法
能够解决突发流量
令牌桶算法是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。
典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。
令牌桶是一个存放固定容量令牌(token)的桶,按照固定速率往桶里添加令牌;令牌桶算法实际上由三部分组成:两个流和一个桶,分别是 令牌流、数据流和令牌桶
令牌流与令牌桶
系统会以一定的速度生成令牌,并将其放置到令牌桶中,可以将令牌桶想象成一个缓冲区(可以用队列这种数据结构来实现),当缓冲区填满的时候,新生成的令牌会被扔掉。这里有两个变量很重要:
- 第一个是生成令牌的速度,一般称为 rate 。比如,我们设定 rate = 2 ,即每秒钟生成 2 个令牌,也就是每 1/2 秒生成一个令牌;
- 第二个是令牌桶的大小,一般称为 burst 。比如,我们设定 burst = 10 ,即令牌桶最大只能容纳 10 个令牌。

有以下三种情形可能发生:
- 数据流的速率 等于 令牌流的速率。这种情况下,每个到来的数据包或者请求都能对应一个令牌,然后无延迟地通过队列;
- 数据流的速率 小于 令牌流的速率。通过队列的数据包或者请求只消耗了一部分令牌,剩下的令牌会在令牌桶里积累下来,直到桶被装满。剩下的令牌可以在突发请求的时候消耗掉。
- 数据流的速率 大于 令牌流的速率。这意味着桶里的令牌很快就会被耗尽。导致服务中断一段时间,如果数据包或者请求持续到来,将发生丢包或者拒绝响应。