云商城-服务安全控制
第13章 服务安全控制
课程目标
1、Gateway限流
1)Gateway限流方案
2)基于令牌桶限流实现
2、Nginx限流
1)Nginx速率限流
2)Nginx并发量限流
3、Redis集群应用
1)Redis集群搭建
2)Redis扩容与数据迁移
4、缓存灾难处理
1)布隆过滤器原理
2)Guava布隆过滤使用
3)Redis布隆过滤器实战
1 Gateway限流
在高并发的系统中,往往需要在系统中做限流,一方面是为了防止大量的请求使服务器过载,导致服务不可用,另一方面是为了防止网络攻击。
1.1 常见限流方案
常见的限流方式,比如Hystrix适用线程池隔离,超过线程池的负载,走熔断的逻辑。在一般应用服务器中,比如tomcat容器也是通过限制它的线程数来控制并发的;也有通过时间窗口的平均速度来控制流量。常见的限流纬度有比如通过Ip来限流、通过uri来限流、通过用户访问频次来限流。
一般限流都是在网关这一层做,比如Nginx、Openresty、kong、zuul、Spring Cloud Gateway等;也可以在应用层通过Aop这种方式去做限流。
我们做Java项目开发,如果是微服务一般可以把限流配置在微服务网关中(SpringCloud Gateway)。
1)计数器算法
计数器算法采用计数器实现限流有点简单粗暴,一般我们会限制一秒钟的能够通过的请求数,比如限流qps为100,算法的实现思路就是从第一个请求进来开始计时,在接下去的1s内,每来一个请求,就把计数加1,如果累加的数字达到了100,那么后续的请求就会被全部拒绝。等到1s结束后,把计数恢复成0,重新开始计数。
2)漏桶算法
漏桶算法内部有一个容器,类似生活用到的漏斗,当请求进来时,相当于水倒入漏斗,然后从下端小口慢慢匀速的流出。不管上面流量多大,下面流出的速度始终保持不变。不管服务调用方多么不稳定,通过漏桶算法进行限流,每10毫秒处理一次请求。因为处理的速度是固定的,请求进来的速度是未知的,可能突然进来很多请求,没来得及处理的请求就先放在桶里,既然是个桶,肯定是有容量上限,如果桶满了,那么新进来的请求就丢弃。漏桶算法存在一个缺陷,无法应对短时间的突发流量,比如双十一抢购、秒杀活动开始。
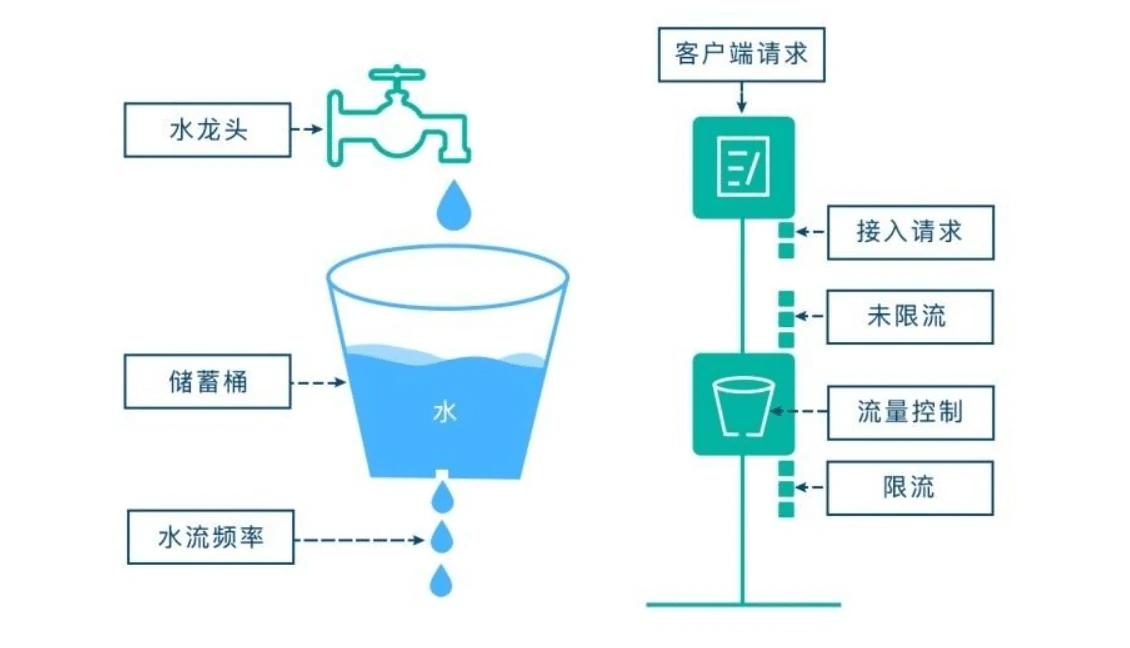
3)令牌桶算法
令牌桶算法是对漏桶算法的一种改进,桶算法能够限制请求调用的速率,而令牌桶算法能够在限制调用的平均速率的同时还允许一定程度的突发调用。在令牌桶算法中,存在一个桶,用来存放固定数量的令牌。算法中存在一种机制,以一定的速率往桶中放令牌。每次请求调用需要先获取令牌,只有拿到令牌,才有机会继续执行,否则选择选择等待可用的令牌、或者直接拒绝。放令牌这个动作是持续不断的进行,如果桶中令牌数达到上限,就丢弃令牌,所以就存在这种情况,桶中一直有大量的可用令牌,这时进来的请求就可以直接拿到令牌执行,比如设置qps为100,那么限流器初始化完成一秒后,桶中就已经有100个令牌了,这时服务还没完全启动好,等启动完成对外提供服务时,该限流器可以抵挡瞬时的100个请求。所以,只有桶中没有令牌时,请求才会进行等待,最后相当于以一定的速率执行。

1.2 Gateway令牌桶限流
Spring Cloud Gateway官方就提供了RequestRateLimiterGatewayFilterFactory这个类,适用Redis和lua脚本实现了令牌桶的方式。具体实现逻辑在RequestRateLimiterGatewayFilterFactory类中,lua脚本在如下图所示的文件夹中:
我们接下来把Redis作为令牌桶实现限流
1)引入依赖
在mall-api-gateway中引入如下依赖:
<!--基于Redis实现限流-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
<version>2.2.10.RELEASE</version>
</dependency>
2)增加限流方式
限流通常要根据某一个参数值作为参考依据来限流,比如每个IP每秒钟只能访问2次,此时是以IP为参考依据,我们分别创建根据IP限流、根据Uri限流的对象,该对象需要实现接口KeyResolver
创建com.gupaoedu.vip.mall.api.limit.IpKeyResolver根据IP限流,代码如下:
public class IpKeyResolver implements KeyResolver {
/***
* 根据IP限流
* @param exchange
* @return
*/
@Override
public Mono<String> resolve(ServerWebExchange exchange) {
return Mono.just(exchange.getRequest().getRemoteAddress().getAddress().getHostAddress());
}
}
创建根据URI限流com.gupaoedu.vip.mall.api.limit.UriKeyResolver,代码如下:
public class UriKeyResolver implements KeyResolver {
/***
* 根据URI限流
* @param exchange
* @return
*/
@Override
public Mono<String> resolve(ServerWebExchange exchange) {
return Mono.just(exchange.getRequest().getURI().getPath());
}
}
3)指定限流方式
我们如果需要根据IP限流,则需要将IpKeyResolver的实例交给Spring容器管理,如果需要根据URI实现限流,就需要将UriKeyResolver的实例交给Spring容器管理。
/***
* IP限流
* @return
*/
@Primary
@Bean(name="ipKeyResolver")
public KeyResolver userIpKeyResolver() {
return new IpKeyResolver();
}
/***
* uri限流
* @return
*/
@Bean(name="uriKeyResolver")
public KeyResolver userUriKeyResolver() {
return new UriKeyResolver();
}
4)限流配置
在mall-api-gateway的核心配置文件中添加如下配置:

在上面的配置文件,配置了RequestRateLimiter的限流过滤器,该过滤器需要配置三个参数:
- burstCapacity,令牌桶总容量。
- replenishRate,令牌桶每秒填充平均速率。
- key-resolver,用于限流的键的解析器的 Bean 对象的名字。它使用 SpEL 表达式根据#{@beanName}从 Spring 容器中获取 Bean 对象。
此时我们请求http://192.168.1.104:9001/mall/brand/category/11159不停刷新进行测试,效果如下:

2 Nginx限流
前面我们学习了微服务网关Gateway限流,它主要实现了对后端服务的保护,针对流量陡增和无效请求过滤,我们更需要用到Nginx限流,接下来我们学习Nginx限流。
2.1 Nginx速率限流
Nginx现在已经是最火的负载均衡之一,在流量陡增的互联网面前,接口限流也是很有必要的,尤其是针对高并发的场景。Nginx的限流主要是两种方式:限制访问频率和限制并发连接数。
我们先配置一个nginx速率限流,再来讲解速率限流。在服务器上秒杀详情页这里,我们配置速率限流。
1)语法
Nginx中我们使用ngx_http_limit_req_module模块来限制请求的访问频率,基于漏桶算法原理实现。接下来我们使用 nginx limit_req_zone 和 limit_req 两个指令,限制单个IP的请求处理速率:
语法:limit_req_zone key zone rate
key:定义限流对象,binary_remote_addr 是一种key,表示基于 remote_addr(客户端IP) 来做限流,binary_ 的目的是压缩内存占用量。
zone:定义共享内存区来存储访问信息, myRateLimit:10m 表示一个大小为10M,名字为myRateLimit的内存区域。1M能存储16000 IP地址的访问信息,10M可以存储16W IP地址访问信息。
rate:用于设置最大访问速率,rate=10r/s 表示每秒最多处理10个请求。Nginx 实际上以毫秒为粒度来跟踪请求信息,因此 10r/s 实际上是限制:每100毫秒处理一个请求。这意味着,自上一个请求处理完后,若后续100毫秒内又有请求到达,将拒绝处理该请求。
2)速率限流实战

我们可以测试http://192.168.100.130/msitems/1.html频繁刷新看看效果:

3)突发流量缓冲
按上面的配置在流量突然增大时,超出的请求将被拒绝,无法处理突发流量,那么在处理突发流量的时候,该怎么处理呢?Nginx提供了 burst 参数来解决突发流量的问题,并结合 nodelay 参数一起使用。burst 译为突发、爆发,表示在超过设定的处理速率后能额外处理的请求数。
burst=5 nodelay表示这5个请求立马处理,不能延迟,相当于特事特办。不过,即使这5个突发请求立马处理结束,后续来了请求也不会立马处理。burst=5 相当于缓存队列中占了5个坑,即使请求被处理了,这5个位置这只能按 100ms一个来释放。这就达到了速率稳定,突发然流量也能正常处理的效果。
2.2 Nginx并发量限流
Nginx 的ngx_http_limit_conn_module模块提供了对资源连接数进行限制的功能,使用 limit_conn_zone 和 limit_conn 两个指令就可以了。
limit_conn perip 20 : 对应的key是 $binary_remote_addr,表示限制单个IP同时最多能持有20个连接。
limit_conn perserver 100 : 对应的key是 $server_name,表示虚拟主机(server) 同时能处理并发连接的总数。注意,只有当 request header 被后端server处理后,这个连接才进行计数。
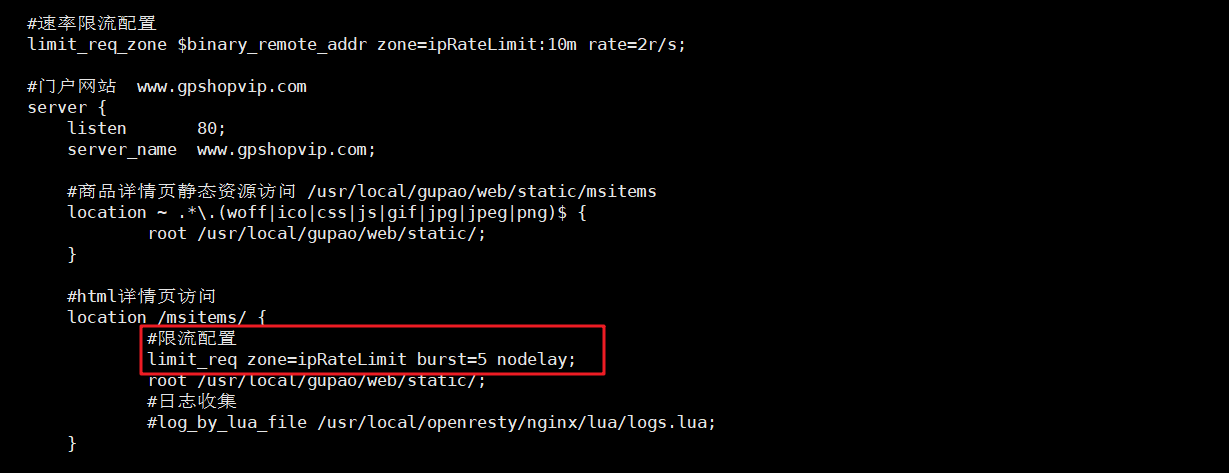
修改nginx.conf配置,如下:

完整配置如下:
#速率限流配置
limit_req_zone $binary_remote_addr zone=ipRateLimit:10m rate=2r/s;
#并法量限流-单个IP控制
limit_conn_zone $binary_remote_addr zone=perip:10m;
#并法量限流-整个服务控制
limit_conn_zone $server_name zone=perserver:10m;
#门户网站 www.gpshopvip.com
server {
listen 80;
server_name www.gpshopvip.com;
#商品详情页静态资源访问 /usr/local/gupao/web/static/msitems
location ~ .*\.(woff|ico|css|js|gif|jpg|jpeg|png)$ {
root /usr/local/gupao/web/static/;
}
#html详情页访问
location /msitems/ {
#限流配置
#limit_req zone=ipRateLimit burst=5 nodelay;
#并发量限流
limit_conn perip 20;
limit_conn perserver 100;
root /usr/local/gupao/web/static/;
#日志收集
#log_by_lua_file /usr/local/openresty/nginx/lua/logs.lua;
}
}
2.3 Nginx黑白名单
有时候会有一些恶意IP攻击服务器,会基于程序频繁发起请求对服务器造成巨大压力,我们此时可以使用Nginx的黑名单功能实现黑名单过滤操作。我们首先需要配置黑名单IP,黑名单IP我们可以记录到一个配置文件中,比如配置到blockip.conf文件中:
配置固定IP为黑名单:
deny 192.168.100.1;
在nginx.conf中引入blockip.conf,可以放到http, server, location语句块,配置如下:
#黑名单
include blockip.conf;
此时在192.168.100.1的IP上访问服务器,会报如下错误:

屏蔽ip的配置文件既可以屏蔽单个ip,也可以屏蔽ip段,或者只允许某个ip或者某个ip段访问。
# 屏蔽单个ip访问
deny IP;
# 允许单个ip访问
allow IP;
# 屏蔽所有ip访问
deny all;
# 允许所有ip访问
allow all;
#屏蔽整个段即从123.0.0.1到123.255.255.254访问的命令
deny 123.0.0.0/8
#屏蔽IP段即从123.45.0.1到123.45.255.254访问的命令
deny 124.45.0.0/16
#屏蔽IP段即从123.45.6.1到123.45.6.254访问的命令
deny 123.45.6.0/24
如果你想实现这样的应用,除了几个IP外,其他全部拒绝,那需要你在blockip.conf中这样写:
allow 192.168.100.1;
allow 192.168.100.2;
deny all;
思考:如果此时需要动态配置黑白名单,该如何操作?
动态黑白名单,可以采用Lua+Redis实现,将黑名单存入到Redis缓存,每次执行请求时,先获取用户IP,匹配IP是否属于黑名单,如果是,则不让请求,如果不是,则放行。
3 缓存安全控制
在项目中,为了提升数据处理效率,我们经常会加入缓存,而关于缓存又会存在很多问题,比如扩容、击穿、穿透、缓存雪崩等灾难,关于这些灾难,我们来实现一下解决方案。
3.1 Redis集群搭建
在生产环境,Redis如果是单节点会存在单点故障,所以一般都是集群环境,所以我们一会先搭建集群,再在Redis集群环境中实现Redis缓存高级操作。
3.1.1 Redis集群原理
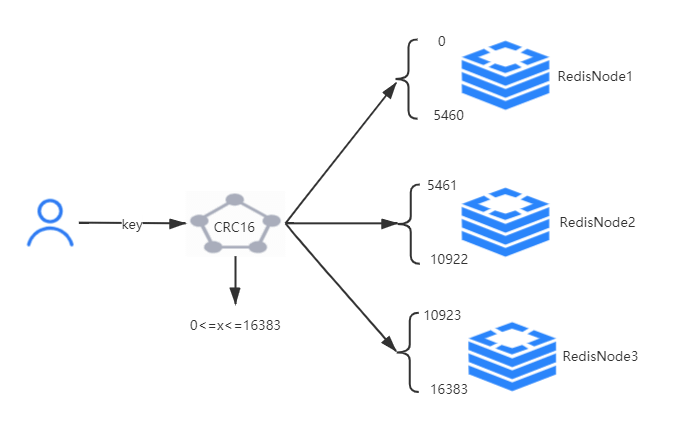
在做Redis集群前,我们先了解一下Redis集群原理:
1:无论对Redis执行增加、删除、查询操作,都会操作一个key
2:无论什么key,经过CRC16算法取模,结果都在0-16383之间,这16384个值被称为哈希槽
3:如果我们现在有一个Redis集群,集群有3个节点,会为每个节点分配一定哈希槽
RedisNode1:0-5460
RedisNode2:5461-10922
RedisNode3:10923-16383
4:每次做增加、删除、查询时,先对key进行CRC16算法取模,计算哈希槽的值
5:根据哈希槽的值重定向当前链接到指定节点上,并执行操作
Redis集群虽然能降低每个节点的载荷,但也存在宕机的风险,此时我们应该给每个节点安装一个从节点,当主节点宕机的时候,可以切换至从节点,添加从节点后,架构图如下:

3.1.2 Docker安装Redis集群
我们使用Docker容器安装Redis集群,准备6台机器(我们在1台机器上模拟):
| 节点 | IP | 端口 |
|---|---|---|
| RedisNode1 | 192.168.100.130 | 7001 |
| RedisNode2 | 192.168.100.130 | 7002 |
| RedisNode3 | 192.168.100.130 | 7003 |
| RedisNode4 | 192.168.100.130 | 7004 |
| RedisNode5 | 192.168.100.130 | 7005 |
| RedisNode6 | 192.168.100.130 | 7006 |
1)创建网络
创建网络(各个Redis集群节点都在同一网段下数据交换,安全性更高,传输效率也会更高):
docker network create redis-net
2)创建Redis配置
我们可以基于shell脚本批量创建每个Redis的配置文件,再采用shell脚本为脚本批量填充数据,再创建docker容器,我们可以先写一个Redis配置的模板文件redis-config.tmpl
#端口
port ${PORT}
#非保护模式
protected-mode no
#启用集群模式
cluster-enabled yes
cluster-config-file nodes.conf
#超时时间
cluster-node-timeout 5000
cluster-announce-ip 192.168.100.130
cluster-announce-port ${PORT}
cluster-announce-bus-port 1${PORT}
#开启aof持久化策略
appendonly yes
#后台运行
#daemonize yes
pidfile /var/run/redis_${PORT}.pid
3)Shell创建docker容器
我们创建一个shell脚本,从7001循环到7006,以上面的redis-config.tmpl模板为基础,批量创建每个redis节点的配置文件,并创建对应容器,文件名字叫install.sh,将改文件设置为可执行文件:
#!/bin/bash
#在/usr/local/gupao/redis-cluster下生成conf和data目标,并生成配置信息
for port in `seq 7001 7006`;
do
mkdir -p ./${port}/conf && PORT=${port} envsubst < ./redis-config.tmpl > ./${port}/conf/redis.conf && mkdir -p ./${port}/data;
done
#创建6个redis容器
for port in `seq 7001 7006`;
do
docker run -d -it -p ${port}:${port} -p 1${port}:1${port} -v /usr/local/gupao/redis-cluster/${port}/conf/redis.conf:/usr/local/etc/redis/redis.conf -v /usr/local/gupao/redis-cluster/${port}/data:/data --privileged=true --restart always --name redis-${port} --net redis-net --sysctl net.core.somaxconn=1024 redis redis-server /usr/local/etc/redis/redis.conf;
done
#查找ip
for port in `seq 7001 7006`;
do
echo -n "$(docker inspect --format '{{ (index .NetworkSettings.Networks "redis-net").IPAddress }}' "redis-${port}")":${port}" ";
done
#换行
echo -e "\n"
#输入信息
read -p "输入要进入的Docker容器名字,默认redis-7001:" DOCKER_NAME
#判断是否为空
if [ ! $DOCKER_NAME ];
then DOCKER_NAME='redis-7001';
fi
#进入容器
docker exec -it redis-7001 /bin/bash
创建文件后执行授权:
chmod +x install.sh
此时执行./install.sh就能安装7001-7006的容器。
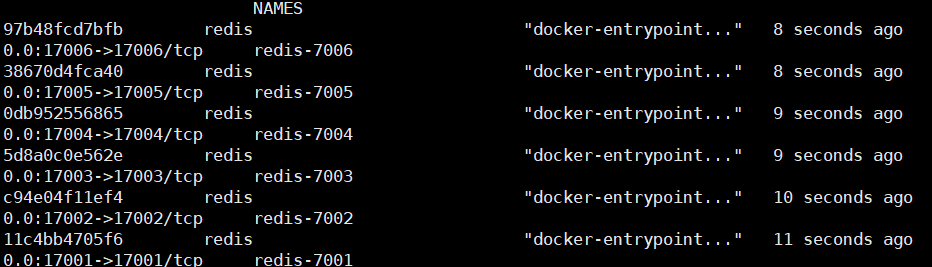
执行这一步之后,也只是容器安装好了,开启了集群,但哪些节点创建一个集群组还并未操作,我们需要用到redis-cli客户端工具来创建集群组:
./redis-cli --cluster create 172.20.0.2:7001 172.20.0.3:7002 172.20.0.4:7003 172.20.0.5:7004 172.20.0.6:7005 172.20.0.7:7006 --cluster-replicas 1
效果如下:
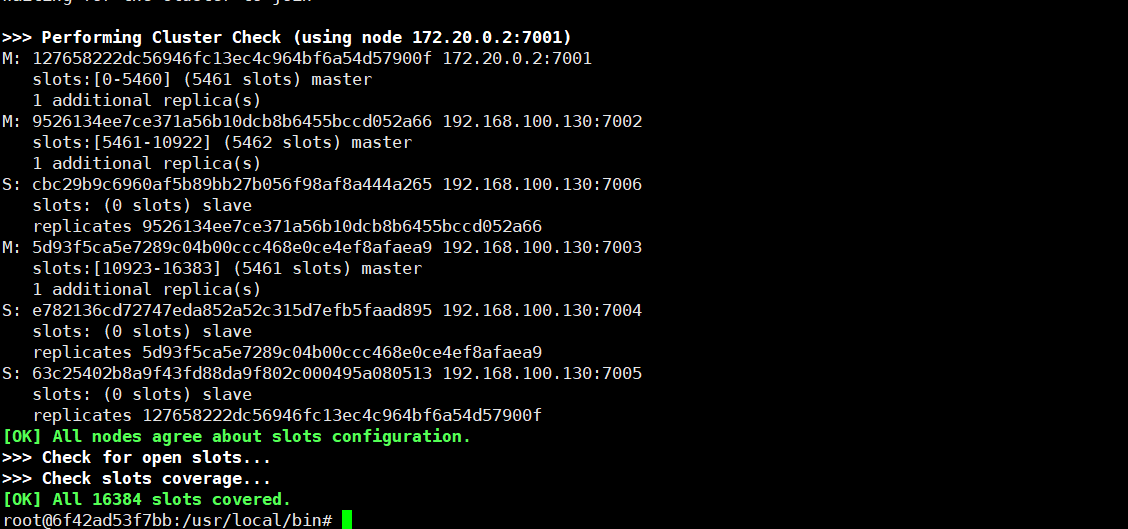
此时集群管理如下:
7001(Master) 7005(Slave)
7002(Master) 7006(Slave)
7003(Master) 7004(Slave)
关于创建集群中的相关参数我们做如下说明:
Cluster Manager Commands:
create host1:port1 ... hostN:portN #创建集群
--cluster-replicas <arg> #从节点个数
check host:port #检查集群
--cluster-search-multiple-owners #检查是否有槽同时被分配给了多个节点
info host:port #查看集群状态
fix host:port #修复集群
--cluster-search-multiple-owners #修复槽的重复分配问题
reshard host:port #指定集群的任意一节点进行迁移slot,重新分slots
--cluster-from <arg> #需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-to <arg> #slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-slots <arg> #需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。
--cluster-yes #指定迁移时的确认输入
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10
--cluster-replace #是否直接replace到目标节点
rebalance host:port #指定集群的任意一节点进行平衡集群节点slot数量
--cluster-weight <node1=w1...nodeN=wN> #指定集群节点的权重
--cluster-use-empty-masters #设置可以让没有分配slot的主节点参与,默认不允许
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-simulate #模拟rebalance操作,不会真正执行迁移操作
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,默认值为10
--cluster-threshold <arg> #迁移的slot阈值超过threshold,执行rebalance操作
--cluster-replace #是否直接replace到目标节点
add-node new_host:new_port existing_host:existing_port #添加节点,把新节点加入到指定的集群,默认添加主节点
--cluster-slave #新节点作为从节点,默认随机一个主节点
--cluster-master-id <arg> #给新节点指定主节点
del-node host:port node_id #删除给定的一个节点,成功后关闭该节点服务
call host:port command arg arg .. arg #在集群的所有节点执行相关命令
set-timeout host:port milliseconds #设置cluster-node-timeout
import host:port #将外部redis数据导入集群
--cluster-from <arg> #将指定实例的数据导入到集群
--cluster-copy #migrate时指定copy
--cluster-replace #migrate时指定replace
4)集群测试
集群安装好了后,我们可以使用redis-cli进行测试:
#登录redis集群
root@6f42ad53f7bb:/usr/local/bin# ./redis-cli -p 7001 -c
#添加数据
127.0.0.1:7001> set zhangsan SDFDSFDSF.DSFSDFSDFS.FHBSDFDSFSDFF
#自动重定向到7003节点
-> Redirected to slot [12767] located at 192.168.100.130:7003
OK
192.168.100.130:7003>
5)卸载Docker容器
如果我们想卸载安装的docker容器,可以创建一个文件uninstall.sh:
#!/bin/bash
docker stop redis-7001 redis-7002 redis-7003 redis-7004 redis-7005 redis-7006
docker rm redis-7001 redis-7002 redis-7003 redis-7004 redis-7005 redis-7006
rm -rf 7001 7002 7003 7004 7005 7006
再给uninstall.sh添加可执行权限:
chmod +x uninstall.sh
执行该文件即可卸载7001-7006所有docker容器了
3.2 Java连接Redis集群
在java客户端连接Redis集群,只需要修改配置文件bootstrap.yml中redis链接即可:
redis:
cluster:
nodes: 192.168.100.130:7001,192.168.100.130:7002,192.168.100.130:7003,192.168.100.130:7004,192.168.100.130:7005,192.168.100.130:7006
我们可以把mall-permission-service和mall-api-gateway中redis链接地址换成集群服务地址,测试后我们可以发现权限数据正常入库:

3.3 扩容与迁移
在生产环境,如果缓存数据量过大,就有扩容需求,针对Redis进行扩容,其实只用使用它的指令即可,但无论怎么使用,都和Redis集群的原理有关,也就是key经过CRC16算法取模最终的值在0至16383范围之间。
3.3.1 新节点创建
我们需要做扩容操作,所以需要先创建一个节点,创建单个节点我们可以把之前的脚本修改一下,创建单个节点的文件oneinstall.sh:
#!/bin/bash
#在/usr/local/gupao/redis-cluster下生成conf和data目标,并生成配置信息
#换行
echo -e "\n"
#输入信息
read -p "请输入容器端口:" DOCKER_PORT
#输入端口赋值
port=$DOCKER_PORT;
echo -e "$port"
#创建配置文件
mkdir -p ./${port}/conf && PORT=${port} envsubst < ./redis-config.tmpl > ./${port}/conf/redis.conf && mkdir -p ./${port}/data;
#创建redis容器
docker run -d -it -p ${port}:${port} -p 1${port}:1${port} -v /usr/local/gupao/redis-cluster/${port}/conf/redis.conf:/usr/local/etc/redis/redis.conf -v /usr/local/gupao/redis-cluster/${port}/data:/data --privileged=true --restart always --name redis-${port} --net redis-net --sysctl net.core.somaxconn=1024 redis redis-server /usr/local/etc/redis/redis.conf;
#查找ip
echo -n "启动$(docker inspect --format '{{ (index .NetworkSettings.Networks "redis-net").IPAddress }}' "redis-${port}")":${port}" 成功!";
echo -e "\n"
给oneinstall.sh添加可执行权限,并执行该脚本:
#添加可执行权限
chmod +x oneinstall.sh
#创建新的节点
./oneinstall.sh
#输入7007端口
7007
此时7007节点创建完成:

3.3.2 扩容
我们要进行扩容,可以先查看当前集群状态:
#查看集群状态
cluster nodes
状态信息如下:

我们现在开始执行节点增加,也就是扩容操作:
./redis-cli --cluster add-node 192.168.100.130:7007 192.168.100.130:7001
执行后,效果如下:
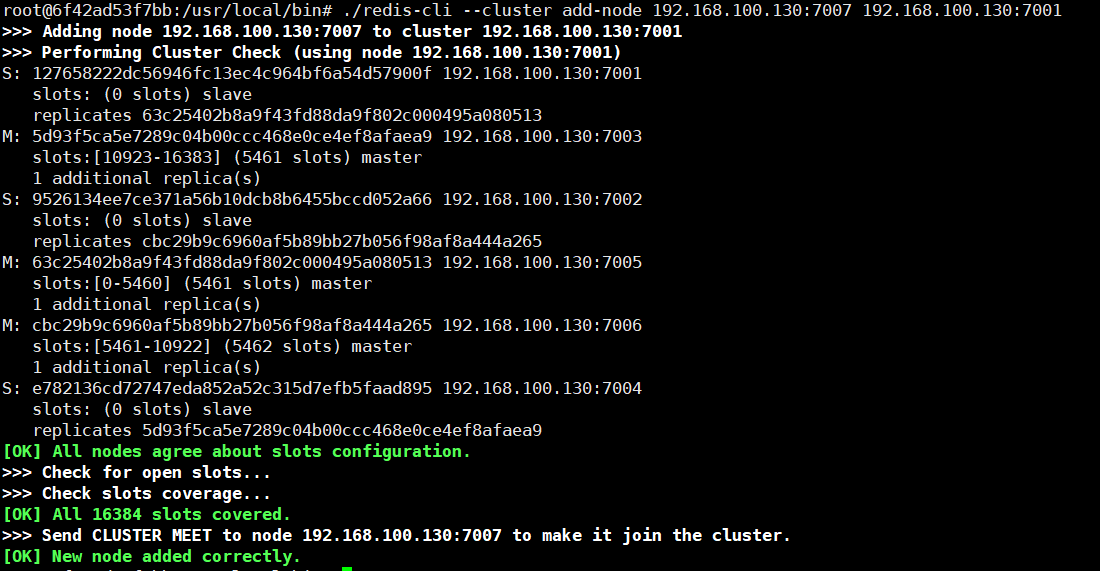
此时我们再查看状态:cluster nodes

此时节点已经增加进来,但目前没有分配任何哈希槽,所以无论做数据增加还是删除以及查询,都和它没有一毛钱关系,因此我们还要把部分哈希槽迁移到该节点上,同时被迁移的节点上对应数据也会跟着一起迁移过来,迁移命令如下:
./redis-cli --cluster reshard 192.168.100.130:7003 --cluster-from 5d93f5ca5e7289c04b00ccc468e0ce4ef8afaea9 --cluster-to 889a13a1e1761f1e83c25e41287d1c463175d467 --cluster-slots 100
参数说明:
5d93f5ca5e7289c04b00ccc468e0ce4ef8afaea9 指的是7003节点
889a13a1e1761f1e83c25e41287d1c463175d467 指定是7007节点
表示将7003节点中100个哈希槽迁移到7007上来
我们再查看状态:

思考:如何实现收容?
收容其实也很简单,也是使用命令即可,要做2个操作
1:哈希槽迁移
2:删除节点
4 缓存灾难解决
缓存虽然能大幅提升系统数据处理效率,但也存在一些潜在风险。
缓存穿透:
缓存穿透,是指查询一个数据库一定不存在的数据。正常的使用缓存流程大致是,数据查询先进行缓存查询,如果key不存在或者key已经过期,再对数据库进行查询,并把查询到的对象,放进缓存。如果数据库查询对象为空,则不放进缓存。
缓存击穿:
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
缓存雪崩:
缓存雪崩,是指在某一个时间段,缓存集中过期失效。
4.1 布隆过滤器
布隆过滤器(Bloom Filter)是一种空间效率高的概率型数据结构,它专门用来检测集合中是否存在特定的元素。
布隆过滤器采用了散列表(又叫哈希表,Hash table)的数据结构,它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit Array)中的一个点。这样一来,我们只要看看这个点是不是 1 就知道可以集合中有没有它了。这就是布隆过滤器的基本思想。
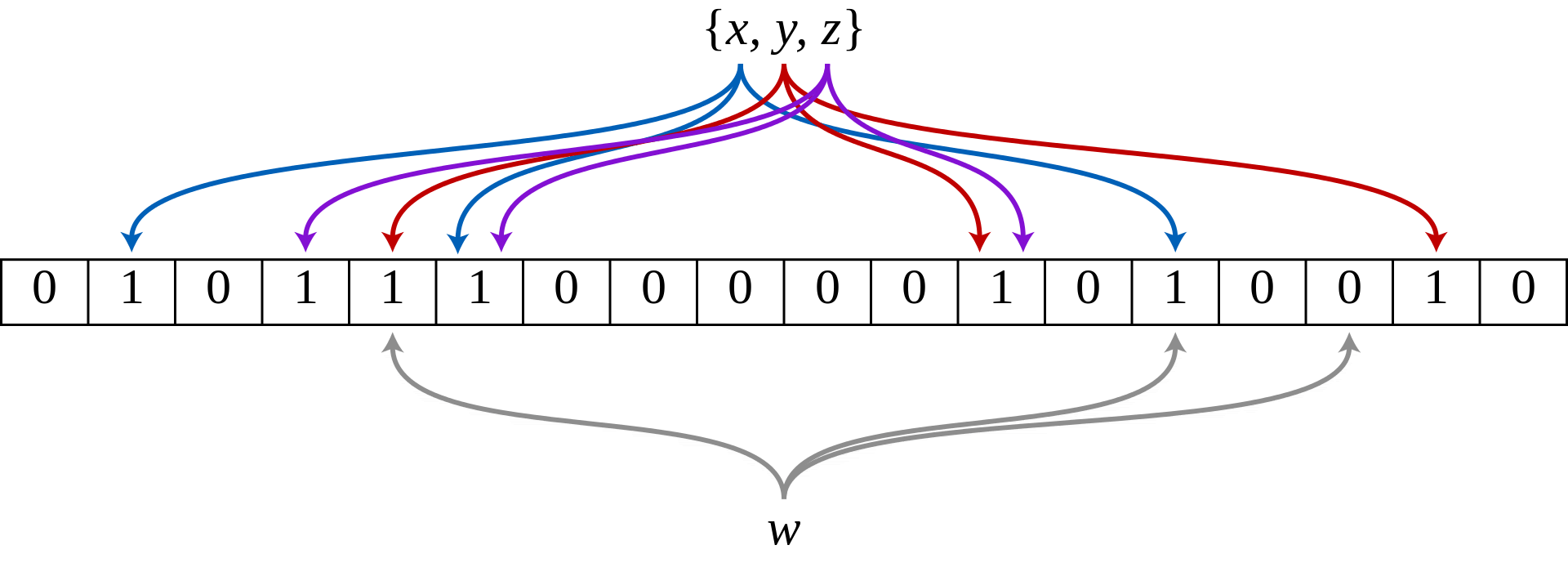
常用场景:
1:垃圾邮件检测
2:爬虫去重
3:缓存穿透
优点:
1:不需要存储数据本身,只用比特表示,因此空间占用相对于传统方式有巨大的优势,并且能够保密数据;
2:时间效率较高;
缺点:
1:存在假阳性的概率,不适用于任何要求100%准确率的情境;
2:只能插入和查询元素,不能删除元素;
4.2 Guava布隆过滤器
google的guava工具包中就提供了布隆过滤器,而且是当前主流的布隆过滤器之一,我们可以直接在项目中使用它。我们来学习一下它的使用:
1)引入依赖
<!--google的布隆过滤器-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>
2)编写测试
public class BloomFilterTest {
private static int size = 1000000;
//Google的布隆过滤器
private static BloomFilter<Integer> bloomFilter =BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) {
//放一百万个key到布隆过滤器中
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<Integer>(1000);
//取10000个不在过滤器里的值,看看有多少个会被认为在过滤器里
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}
}
单机更适合使用guava布隆过滤器,但如果是在分布式应用中,我们推荐使用Redis的布隆过滤器,可以通过Redis打破跨服务通信。
4.3 Redis布隆过滤器
Redis 实现布隆过滤器的底层就是通过 bitmap 这种数据结构,当前使用bitmap比较好用的一个客户端工具——Redisson,关于Redisson前面我们已经学习过了,我们接下来演示基于Redisson实现布隆过滤器的操作实战。
4.3.1 功能说明
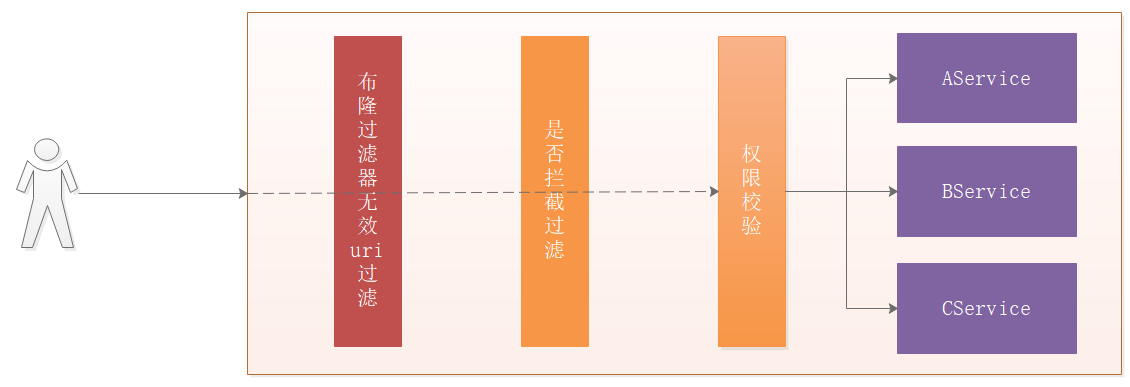
我们系统中需要对权限进行校验,我们可以把权限url存入到bitmap中,每次进行权限校验之前,可以先看看布隆过滤器中是否存在用户请求的路径,如果存在则进行权限校验,如果不存在,直接拒绝用户请求,这样可以大幅降低无效请求。
4.3.2 路径初始化
在mall-permission-service中引入依赖:
<!--Redisson分布式锁-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.8.2</version>
</dependency>
在mall-permission-service中创建Redisson的锁操作对象:
@Configuration
public class RedissLock {
/***
* 创建RedissonClient对象
* 创建锁、解锁
* @return
*/
@Bean
public RedissonClient redissonClient(){
//创建Config
Config config = new Config();
//集群实现
config.useClusterServers()
.setScanInterval(2000)
.addNodeAddress(
"redis://192.168.100.130:7001",
"redis://192.168.100.130:7002",
"redis://192.168.100.130:7003",
"redis://192.168.100.130:7004",
"redis://192.168.100.130:7005",
"redis://192.168.100.130:7006");
//创建RedissonClient
return Redisson.create(config);
}
}
在com.gupaoedu.vip.mall.permission.init.InitPermission中实现路径初始化:
@Autowired
private RedissonClient redissonClient;
/***
* 权限初始化加载
* @param args
* @throws Exception
*/
@Override
public void run(ApplicationArguments args) throws Exception {
//...略;
//uri初始化到布隆过滤器中
RBloomFilter<String> filters = redissonClient.getBloomFilter("UriBloomFilterArray");
//初始化数组长度以及误判概率
filters.tryInit(10000L,0.001);
//这里只演示完全匹配,通配符匹配还需要额外处理
for (Permission permission : permissionMatch0) {
filters.add(permission.getUrl());
}
}
此时我们启动服务初始化数据如下:

4.3.3 无效路径过滤
在mall-api-gateway中引入依赖:
<!--Redisson分布式锁-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.8.2</version>
</dependency>
在mall-api-gateway中创建Redisson的锁操作对象:
@Configuration
public class RedissLock {
/***
* 创建RedissonClient对象
* 创建锁、解锁
* @return
*/
@Bean
public RedissonClient redissonClient(){
//创建Config
Config config = new Config();
//集群实现
config.useClusterServers()
.setScanInterval(2000)
.addNodeAddress(
"redis://192.168.100.130:7001",
"redis://192.168.100.130:7002",
"redis://192.168.100.130:7003",
"redis://192.168.100.130:7004",
"redis://192.168.100.130:7005",
"redis://192.168.100.130:7006");
//创建RedissonClient
return Redisson.create(config);
}
}
在com.gupaoedu.vip.mall.api.permission.AuthorizationIntterceptor中创建方法判断当前uri是否存在,代码如下:
@Autowired
private RedissonClient redissonClient;
/***
* 无效路径过滤
*/
public Boolean isInvalid(String uri){
//获取数组对象
RBloomFilter<Object> bloomFilterArray = redissonClient.getBloomFilter("UriBloomFilterArray");
return bloomFilterArray.contains(uri);
}
在com.gupaoedu.vip.mall.api.filter.ApiFilter执行调用,代码如下:

此时我们访问一个不存在的url = http://192.168.1.104:9001/mall/cart,此时会报出如下错误:

思考:无效路径过滤如果迁移到Nginx中,效率是否更高?该怎么做?
如果将无效路径迁移到Nginx中,效率一定更高,甚至高出几百倍,可以采用Lua+nginx实现。