云商城-热门数据实时收集
第10章 热门数据实时收集
课程目标
1、掌握热门分析收集方案
2、Lua高级语法
1)掌握Lua高级语法指令执行顺序
2)掌握Lua高级语法指令编写位置
3、Kafka使用
1)Kafka安装
2)Kafka创建队列
3)Kafka发送消息
4)Kafka消费消息
4、Lua垂直日志收集
1)Lua垂直日志收集流程
2)Lua实现Kafka操作
3)Lua垂直日志收集
5、Apache Druid大数据实时处理系统
1)Apache Druid安装
2)Apache Druid数据摄入
3)Apache Druid SQL使用
1 热门分析收集方案
在秒杀抢购过程中,热门商品对服务器造成的压力巨大,很有可能直接导致服务器宕机,对热门分析的抢单过程应该单独处理,尤其是抢单过程中慢慢变成热门的商品,对他们要具备发现能力。
1)历史热门分析分析

我们可以从历史交易订单、历史收藏商品、历史购物车记录、历史搜索关键词中分析哪些商品是热门商品,然后将热门商品保存到Redis缓存中,用户每次下单,如果缓存中有数据,证明是热门分析,如果缓存中没有数据,则证明是非热门分析。
2)热门分析发现

上面的方案只能实现历史热门分析分析,但抢购过程中的热门分析我们也要具备发现能力,如上图:
1:用户请求到达Nginx,我们可以通过log_by_lua记录访问日志
2:log_by_lua将日志发送到Kafka,日志也应该是有用的日志,最好做垂直日志收集
3:大数据实时分析系统Apache Druid消费log_by_lua发送的日志
4:java程序定时通过DruidSQL从Apache Druid中分析数据
5:分析的数据如果是热门的,就将数据存入到Redis集群中
从上面的分析流程来讲,我们需要掌握这么几门技术的应用:
1:Nginx
2:Lua
3:Kafka
4:Zookeeper
5:Apache Druid
6:Druid SQL
我们接下来对这几门技术进行学习,然后实现用户访问详情页日志收集。
2 Lua高性能脚本
2.1 Lua介绍
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
Lua特性:
轻量级: 它用标准C语言编写并以源代码形式开放,编译后仅仅一百余K,可以很方便的嵌入别的程序里。
可扩展: Lua提供了非常易于使用的扩展接口和机制:由宿主语言(通常是C或C++)提供这些功能,Lua可以使用它们,就像是本来就内置的功能一样。
其它特性:
1)支持面向过程(procedure-oriented)编程和函数式编程(functional programming);
2)自动内存管理;只提供了一种通用类型的表(table),用它可以实现数组,哈希表,集合,对象;
3)语言内置模式匹配;闭包(closure);函数也可以看做一个值;提供多线程(协同进程,并非操作系统所支持的线程)支持;
4)通过闭包和table可以很方便地支持面向对象编程所需要的一些关键机制,比如数据抽象,虚函数,继承和重载等。
Lua应用场景:
1)游戏开发
2)独立应用脚本
3)Web 应用脚本
4)扩展和数据库插件如:MySQL Proxy 和 MySQL WorkBench
5)安全系统,如入侵检测系统
前面我们已经对Lua语法进行过讲解,此处我们不再对基础语法进行讲解,我们直接学习它的高级操作。
2.2 Lua高级操作
我们用Lua脚本,一般都是和Nginx结合一起使用,那么我们的Lua脚本在请求过来的时候是如何执行的呢,下面是指令执行顺序:
http{
server{
location / {}
}
}

如上面的流程图,我们对关键的指令进行讲解:
1:init_by_lua*:当Nginx的master进程加载Nginx配置文件(加载或重启Nginx进程)时,可以通过该指令控制初始化的配置信息,init_by_lua*是Nginx配置加载的阶段。可以配置在http中。
2:init_worker_by_lua*:当Nginx启动后,会执行init_worker_by_lua*的Lua脚本,该脚本可以用来定期执行相关任务操作,类似java中的定时任务,比如定时检查相关服务的健康状态。可以配置在http中。
3:set_by_lua*:执行Lua代码,并将返回的字符串赋值给$变量,如:set_by_lua_block $res {lua-script-str}表示执行<lua-script-str>代码,并将返回的字符串赋值给$res。可以配置在server,server if,location,location if。
4:rewrite_by_lua*:重写阶段的处理程序,对每个请求执行指定的Lua代码。可以配置在http,server,location,location if。
5:access_by_lua*:在Nginx的access阶段,对每个请求执行Lua的代码,和rewrite_bylua block一样,这些Lua代码可以调用所有的Lua API,并且运行在独立的全局环境(类似于沙盒)中,以新的协程来执行。此阶段一般用来进行权限检查和黑白名单配置。可以配置在http,server,location,location if。
6:content_by_lua*:content_by_lua*:作为内容处理阶段,对每个请求执行<lua-script-str>的代码。和rewrite_by_lua_block一样,这些Lua代码可以调用所有的Lua API,并且运行在独立的全局环境(类似于沙盒)中,以新的协程来执行。可以配置在location,location if。
7:header_filter_by_lua*:在header_filter_by_lua*阶段,对每个请求执行lua代码,以此对响应头进行过滤。常用于对响应头进行添加、删除等操作。可以配置在http,server,location,location if。
8:body_filter_by_lua*:在body_filter_by_lua*阶段执行Lua代码,用于设置输出响应体的过滤器。在此阶段可以修改响应体的内容,如修改字母的大小写、替换字符串等。可以配置在http,server,location,location if。
9:log_by_lua*:在日志请求处理阶段执行lua代码。它不会替换当前access请求的日志,而会运行在access的前面。log_by_lua_block阶段非常适合用来对日志进行定制化处理,且可以实现日志的集群化维护。另外,此阶段属于log阶段,这时,请求已经返回到了客户端,对Ngx_Lua代码的异常影响要小很多。可以配置在http,server,location,location if。
掌握每个执行阶段的用途会让大家在实际开发中更加得心应手,并且我们在后面项目中会运用到相关指令。
3 Kafka使用
Kafka官网http://kafka.apache.org/

关于Kafka详细知识点我们不在这里讲解,我们这里主要应用到Kafka,首先学习下Kafka如何实现生产消息、消费消息,主要满足项目中的应用。
3.1 Kafka安装
关于Kafka安装,我们可以参考http://kafka.apache.org/documentation/#quickstart

为了更方便安装Kafka,我们换种方式采用Docker容器安装,安装如下:
docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=192.168.100.130:2181/kafka -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.100.130:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -v /etc/localtime:/etc/localtime wurstmeister/kafka
参数说明:
KAFKA_BROKER_ID:当前Kafka的唯一ID
KAFKA_ZOOKEEPER_CONNECT:当前Kafka使用的Zookeeper配置信息
KAFKA_ADVERTISED_LISTENERS:对外发布(暴露)的监听器,对外发布监听端口、地址
KAFKA_LISTENERS:监听器,告诉外部连接者要通过什么协议访问指定主机名和端口开放的 Kafka 服务。
注意,安装前务必先安装好Zookeeper,由于上一章我们已经安装了Zookeeper,所以这里不再演示Zookeeper安装流程。
安装好后,我们可以验证一下Kafka是否可用,验证kafka主要使用内部集成的命令实队列创建、现消息发送、消息消费。
3.2 创建队列
我们首先进入到kafka容器的kafka_2.13-2.7.0/bin/目录下,该目录下有很多可执行的脚本,用于队列创建、发送消息、消费消息等,操作如下:
docker exec -it kafka /bin/bash
cd /opt/kafka_2.13-2.7.0/bin/
脚本如下:

创建队列mslogs:
./kafka-topics.sh --create --bootstrap-server 192.168.100.130:9092 --replication-factor 1 --partitions 1 --topic msitemslog
参数说明:
使用kafka-topics.sh创建队列
--create:执行创建一个新的队列操作
--bootstrap-server:需要链接的kafka配置,必填
--replication-factor 1:设置分区的副本数量
--topic mslogs:队列的名字叫mslogs
3.3 发送消息
在kafka容器中执行消息发送(接着上面的步骤执行):
./kafka-console-producer.sh --broker-list 192.168.100.130:9092 --topic mslogs
参数说明:
使用kafka-console-producer.sh实现向kafka的mslogs队列发送消息
--broker-list:指定将消息发给指定的Kafka服务的链接列表配置
--topic mslogs:指定要发送消息的队列名字
此时回车进入下面命令行操作界面:

我们可以发送这样的消息:
{"accesstime":"2020-12-10 16:30:30","uri":"/item/1.html","ip":"119.123.100.2"}
3.4 消息消费
我们执行脚本消费mslogs的数据,命令如下:
./kafka-console-consumer.sh --bootstrap-server 192.168.100.130:9092 --topic msitemslog --from-beginning
参数说明:
使用kafka-console-consumer.sh从kafka中消费mslogs队列的数据
--bootstrap-server:从指定的kafka中读取消息
--topic mslogs:读取队列的名字
--from-beginning:从最开始的数据读取,也就是读取所有数据的意思
消费信息如下:

4 Lua垂直日志收集
我们没有必要做所有日志获取,因为并不是所有日志都有价值,比如关于我们的页面访问可能没有什么分析价值,所以我们应该做垂直日志收集。
4.1 日志收集流程分析
用户访问商品详情页频率越高,那么此时可以推断当前商品是热门商品,所以我们可以收集商品详情页访问日志,收集方式如上图:
1:用户访问商品详情页会经过Nginx
2:此时使用log_by_lua收集日志
3:log_by_lua将日志发送到Kafka
4.2 垂直日志收集实现
4.2.1 秒杀详情页发布
前面我们已经学习过Lua操作流程,我们可以采用log_by_lua实现日志收集,我们首先部署一下秒杀商品详情页,我们将详情页放到/usr/local/gupao/web/static/msitems路径下,再修改nginx.conf配置文件,实现对秒杀详情页的访问操作,配置如下:
#静态资源
location ~ .*\.(woff|ico|css|js|gif|jpg|jpeg|png)$ {
root /usr/local/gupao/web/static/;
}
#所有以msitems开始的请求都到/usr/local/gupao/web/static/路径下找详情页
location /msitems/ {
root /usr/local/gupao/web/static/;
}
注意:只需要对静态页访问收集日志,而图片、样式等静态资源不需要收集日志,所以最好分开写。
http://192.168.100.130/msitems/1.html
我们重新加载nginx配置(nginx -s reload),再访问http://192.168.100.130/msitems/100001956475.html,效果如下:
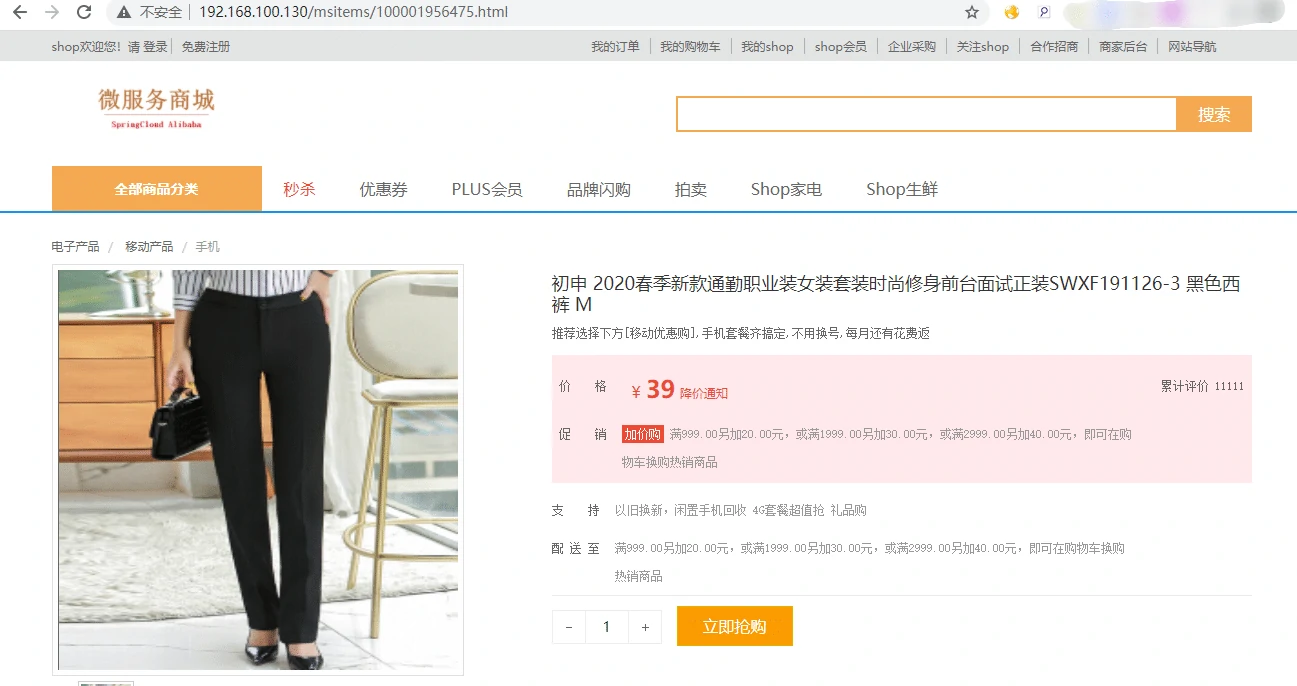
4.2.2 Lua操作Kafka
Lua操作Kafka主要实现MQ消息发送和MQ消息消费,我们项目中主要实现发送消息,此时我们需要写一个Lua库或者借助其他Lua库,写一个Lua库成本比较大,可以借助github上开源的lua库 https://github.com/doujiang24/lua-resty-kafka。
下载安装包:

在下发的参考资料Lua开发工具\Kafka操作库中已经下载好了该库文件lua-resty-kafka-master,将该库文件上传至/usr/local/openresty,并解压unzip lua-resty-kafka-master.zip -d /usr/local/openresty。

nginx要想使用到该lua库,需要在nginx.conf中配置当前lua库文件路径,在http中配置如下:
lua_package_path "/usr/local/openresty/lua-resty-kafka-master/lib/?.lua;;";
4.2.3 Lua实现日志收集
用户访问商品详情页,我们需要使用log_by_lua收集日志,我们先编写一个lua脚本实现日志收集,在之前存放lua脚本的目录/usr/local/openresty/nginx/lua中创建log.lua,脚本代码如下:
--引入json解析库
local cjson = require("cjson")
--kafka库
local producer = require "resty.kafka.producer"
--kafka的链接地址
local broker_list = {
{ host = "192.168.100.130", port = 9092 }
}
--生产者
local pro = producer:new(broker_list,{ producer_type="async"})
--用户IP
local headers=ngx.req.get_headers()
local ip=headers["X-REAL-IP"] or headers["X_FORWARDED_FOR"] or ngx.var.remote_addr or "0.0.0.0"
--消息内容
local logjson = {}
logjson["uri"]=ngx.var.uri
logjson["ip"]=ip
logjson["accesstime"]=os.date("%Y-%m-%d %H:%m:%S")
--发送消息
local offset, err = pro:send("mslogs", nil, cjson.encode(logjson))
if not ok then
ngx.log(ngx.ERR, "kafka send err:", err)
return
end
修改nginx.conf中商品详情页访问的配置,使用log_by_lua_file向Kafka记录日志:
#所有以msitems开始的请求都到/usr/local/gupao/web/static/路径下找详情页
location /msitems/ {
root /usr/local/gupao/web/static/;
#日志记录
log_by_lua_file /usr/local/openresty/nginx/lua/log.lua;
}
重启加载nginx配置(nginx -s reload)并访问http://192.168.100.130/msitems/100001956475.html,我们消费kafka消息,信息如下:

5 Apache Druid海量日志收集
我们接下来需要搞定最后一个知识点Apache Druid大数据实时分析系统,我们可以采用Apache Druid存储海量日志,并对海量日志进行实时分析。
关于Apache Druid学习可以参考中文地址http://www.apache-druid.cn/。
5.1 Apache Druid介绍
当前市面上主流的大数据实时分析数据库很多,我们为什么选择Apache Druid?我们先做个对比:
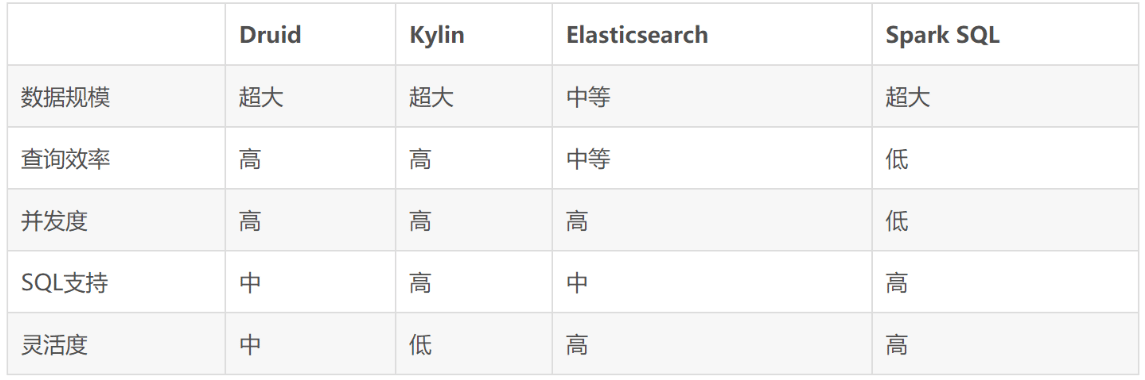
Apache Druid是一个实时分析型数据库,旨在对大型数据集进行快速的查询分析("OLAP"查询)。Druid最常被当做数据库来用以支持实时摄取、高性能查询和高稳定运行的应用场景,同时,Druid也通常被用来助力分析型应用的图形化界面,或者当做需要快速聚合的高并发后端API,Druid最适合应用于面向事件类型的数据。
Druid通常应用于以下场景:
1:点击流分析(Web端和移动端)
2:网络监测分析(网络性能监控)
3:服务指标存储
4:供应链分析(制造类指标)
5:应用性能指标分析
6:数字广告分析
7:商务智能 / OLAP
Druid主要特征:
1:列式存储,Druid使用列式存储,这意味着在一个特定的数据查询中它只需要查询特定的列,这样极地提高了部分列查询场景的性能。另外,每一列数据都针对特定数据类型做了优化存储,从而支持快速的扫描和聚合。
2:可扩展的分布式系统,Druid通常部署在数十到数百台服务器的集群中,并且可以提供每秒数百万条记录的接收速率,数万亿条记录的保留存储以及亚秒级到几秒的查询延迟。
3:大规模并行处理,Druid可以在整个集群中并行处理查询。
4:实时或批量摄取,Druid可以实时(已经被摄取的数据可立即用于查询)或批量摄取数据。
5:自修复、自平衡、易于操作,作为集群运维操作人员,要伸缩集群只需添加或删除服务,集群就会在后台自动重新平衡自身,而不会造成任何停机。如果任何一台Druid服务器发生故障,系统将自动绕过损坏。 Druid设计为7*24全天候运行,无需出于任何原因而导致计划内停机,包括配置更改和软件更新。
6:不会丢失数据的云原生容错架构,一旦Druid摄取了数据,副本就安全地存储在深度存储介质(通常是云存储,HDFS或共享文件系统)中。即使某个Druid服务发生故障,也可以从深度存储中恢复您的数据。对于仅影响少数Druid服务的有限故障,副本可确保在系统恢复时仍然可以进行查询。
7:用于快速过滤的索引,Druid使用CONCISE或Roaring压缩的位图索引来创建索引,以支持快速过滤和跨多列搜索。
8:基于时间的分区,Druid首先按时间对数据进行分区,另外同时可以根据其他字段进行分区。这意味着基于时间的查询将仅访问与查询时间范围匹配的分区,这将大大提高基于时间的数据的性能(__time)。
9:近似算法,Druid应用了近似count-distinct,近似排序以及近似直方图和分位数计算的算法。这些算法占用有限的内存使用量,通常比精确计算要快得多。对于精度要求比速度更重要的场景,Druid还提供了精确count-distinct和精确排序。
10:摄取时自动汇总聚合,Druid支持在数据摄取阶段可选地进行数据汇总,这种汇总会部分预先聚合您的数据,并可以节省大量成本并提高性能。
什么场景下应该使用Druid
1:数据插入频率比较高,但较少更新数据
2:大多数查询场景为聚合查询和分组查询(GroupBy),同时还有一定得检索与扫描查询
3:将数据查询延迟目标定位100毫秒到几秒钟之间
4:数据具有时间属性(Druid针对时间做了优化和设计)
5:在多表场景下,每次查询仅命中一个大的分布式表,查询又可能命中多个较小的lookup表
6:场景中包含高基维度数据列(例如URL,用户ID等),并且需要对其进行快速计数和排序
7:需要从Kafka、HDFS、对象存储(如Amazon S3)中加载数据
Apache Druid架构

如上图,这是官网Apache Druid的架构图:
1.Historicale:加载已生成好的数据文件,以供数据查询。
2.Broker:对外提供数据查询服务。
3.Coordinator:负责Historical Node的数据负载均衡,以及通过Rule管理数据生命周期。
4.元数据库(Metastore):存储druid集群的元数据信息,如Segment的相关信息,一般使用MySQL或PostgreSQL
5.分布式协调服务(Coordination):为Druid集群提供一致性服务,通常为zookeeper
6.数据文件存储(DeepStorage):存储生成的Segment文件,供Historical Node下载,一般为使用HDFS
5.2 Apache Druid安装
安装包下载地址:http://druid.apache.org/downloads.html

当前最新的版本是0.20.0,支持很多丰富功能,因此我们使用该版本。首先下载下来该安装包,并上传到服务器指定目录下/usr/local/gupao,并解压改文件:

我们这里为了方便操作,启动单机版即可,但单机版启动会自动加载Zookeeper,集群版可以自由配置Zookeeper外部节点,但单机版不行。我们前面Kafka也用到了Zookeeper,为了让2个Zookeeper不冲突,我们需要将要安装的Apache Druid的Zookeeper端口换掉,把2181换成3181,在apache-druid-0.20.0目录下执行如下2行命令即可:
sed -i "s/2181/3181/g" `grep 2181 -rl ./`
sed -i "s/druid.zk.service.host=localhost/druid.zk.service.host=localhost:3181/g" `grep druid.zk.service.host=localhost -rl ./`
说明:sed -i "s/原字符串/新字符串/g" grep 原字符串 -rl 所在目录
Druid的时区和国内时区不一致,会比我们的少8个小时,我们需要修改配置文件,批量将时间+8,代码如下:
sed -i "s/Duser.timezone=UTC/Duser.timezone=UTC+8/g" `grep Duser.timezone=UTC -rl ./`
接下来进入到/usr/local/gupao/apache-druid-0.20.0/bin目录下启动Apache Druid即可:
./start-micro-quickstart
启动后,等待20秒我们可以访问Apache Druid的控制台http://192.168.100.130:8888/效果如下:
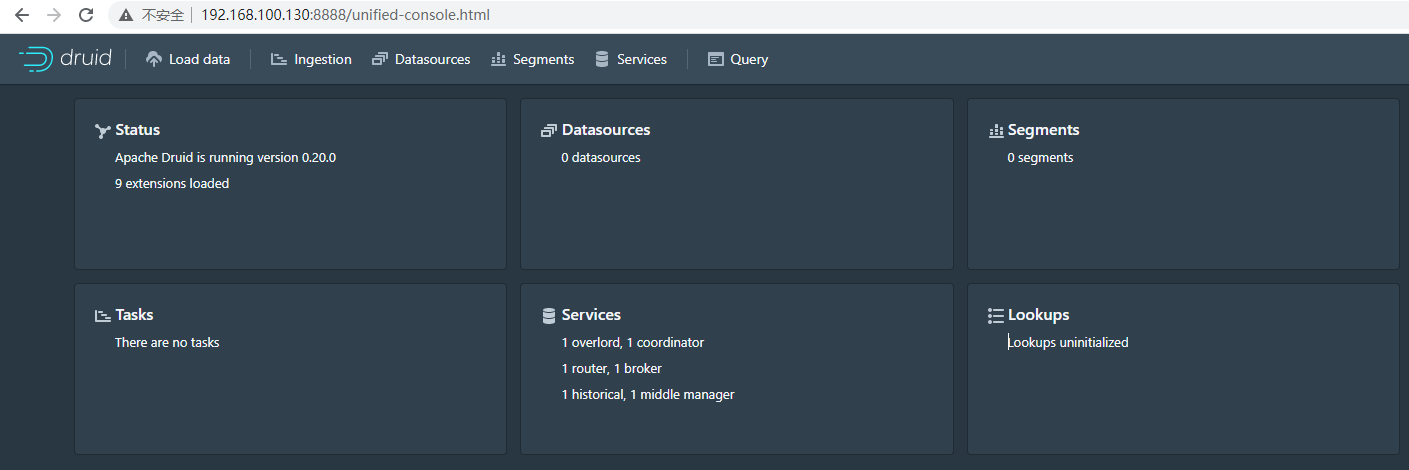
注意:如果需要后台运行,可以直接执行./start-micro-quickstart &
5.3 数据摄入

Apache Druid数据摄入方式支持多种,可以批量从文件中摄入,也可以从实时数据流中摄入,我们接下来对这2种摄入方式分别进行讲解。
5.3.1 文件批量摄入
文件批量摄入主要是把现有的数据批量导入到Apache Druid中,典型的应用就是历史数据分析,我们项目中可以分析历史订单。大家可能会问,数据不是已经存在数据库了吗,为什么还要用Apache Druid做分析?我们这里如果是PB级别数据,用数据库查询很有可能超时,但用Apache Druid查询,效率极高,是MySQL数据库的几百倍甚至更高。
我们按照官网文档学习一下批量文件摄入,打开http://druid.apache.org/docs/latest/tutorials/index.html按照该文档一步一步实现。
点击控制台中的 Load data,选择 Local disk,然后点击 Connect data

在 Base directory 中输入 quickstart/tutorial/, 在 File filter 中输入 wikiticker-2015-09-12-sampled.json.gz。 Base directory 和 File filter 分开是因为可能需要同时从多个文件中摄取数据。
点击 Preview,确保您看到的数据是正确的。
数据定位后,您可以点击"Next: Parse data"来进入下一步。

数据加载器将尝试自动为数据确定正确的解析器。在这种情况下,它将成功确定json。可以随意使用不同的解析器选项来预览Druid如何解析您的数据。
json 选择器被选中后,点击 Next:Parse time 进入下一步来决定您的主时间列。

Druid的体系结构需要一个主时间列(内部存储为名为__time的列)。如果您的数据中没有时间戳,请选择 固定值(Constant Value) 。在我们的示例中,数据加载器将确定原始数据中的时间列是唯一可用作主时间列的候选者。
点击"Next:..."两次完成 Transform 和 Filter 步骤。您无需在这些步骤中输入任何内容。

在这里,您可以调整如何在Druid中将数据拆分为多个段。 由于这是一个很小的数据集,因此在此步骤中无需进行任何调整。
点击完成 Tune 步骤,进入到 Publish 步。

在 Publish 步骤中,我们可以指定Druid中的数据源名称,让我们将此数据源命名为 Wikipedia。最后,单击 Next 来查看您的摄取规范。

这就是您构建的规范,为了查看更改将如何更新规范是可以随意返回之前的步骤中进行更改,同样,您也可以直接编辑规范,并在前面的步骤中看到它,最后点击submit。
您可以进入任务视图,重点关注新创建的任务。任务视图设置为自动刷新,请等待任务成功。
当一项任务成功完成时,意味着它建立了一个或多个段,这些段现在将由Data服务器接收。
从标题导航到 Datasources 视图。

等待直到您的数据源(Wikipedia)出现,加载段时可能需要几秒钟。
一旦看到绿色(完全可用)圆圈,就可以查询数据源。此时,您可以转到 Query 视图以对数据源运行SQL查询。

5.3.2 实时数据流摄入
实时数据流摄入就是我们项目中需要用到的,我们可以利用Kafka实时数据流收集日志,再用Apache Druid消费实时数据流数据。
从kafka读取实时数据流操作文档http://druid.apache.org/docs/latest/tutorials/tutorial-kafka.html
控制台中我们选择Apache Kafka,再点击Connect data

在 Bootstrap servers 输入 192.168.100.130:9092, 在 Topic 输入 mslogs
点击 Preview 后确保您看到的数据是正确的
数据定位后,您可以点击"Next: Parse data"来进入下一步。

数据加载器将尝试自动为数据确定正确的解析器。在这种情况下,它将成功确定json。可以随意使用不同的解析器选项来预览Druid如何解析您的数据。
json 选择器被选中后,点击 Next:Parse time 进入下一步来决定您的主时间列。
Druid的体系结构需要一个主时间列(内部存储为名为__time的列)。如果您的数据中没有时间戳,请选择 固定值(Constant Value) 。在我们的示例中,数据加载器将确定原始数据中的时间列是唯一可用作主时间列的候选者。
点击"Next:..."两次完成 Transform 和 Filter 步骤。您无需在这些步骤中输入任何内容。

在Configure schema中时间精度选择none。
我们将该数据源命名为 mslogs
最后点击 Next 预览摄入规范:

此时提交,然后请求一次http://192.168.100.130/msitems/100001956475.html再看Apache Druid的控制台,会多一个数据库mslogs。

5.4 DruidSQL
Druid SQL是一个内置的SQL层,是Druid基于JSON的本地查询语言的替代品,它由基于 Apache Calcite 的解析器和规划器提供支持。Druid SQL将SQL转换为查询Broker(查询的第一个进程)上的原生Druid查询,然后作为原生Druid查询传递给数据进程。除了在Broker上 转换SQL 的(轻微)开销之外,与原生查询相比,没有额外的性能损失。
5.4.1 DruidSQL语法
查询符号
Druid SQL支持如下结构的SELECT查询:
[ EXPLAIN PLAN FOR ]
[ WITH tableName [ ( column1, column2, ... ) ] AS ( query ) ]
SELECT [ ALL | DISTINCT ] { * | exprs }
FROM { <table> | (<subquery>) | <o1> [ INNER | LEFT ] JOIN <o2> ON condition }
[ WHERE expr ]
[ GROUP BY [ exprs | GROUPING SETS ( (exprs), ... ) | ROLLUP (exprs) | CUBE (exprs) ] ]
[ HAVING expr ]
[ ORDER BY expr [ ASC | DESC ], expr [ ASC | DESC ], ... ]
[ LIMIT limit ]
[ OFFSET index]
[ UNION ALL <another query> ]
FROM
FROM子句可以引用下列任何一个:
来自 druid schema中的 表数据源。 这是默认schema,因此可以将Druid表数据源引用为 druid.dataSourceName 或者简单的 dataSourceName。
来自 lookup schema的 lookups, 例如 lookup.countries。 注意:lookups还可以使用 Lookup函数 来查询。
子查询
列表中任何内容之间的 joins,本地数据源(table、lookup、query)和系统表之间的联接除外。连接条件必须是连接左侧和右侧的表达式之间的相等。
来自于 INFORMATION_SCHEMA 或者 sys schema的 元数据表
WHERE
WHERE子句引用FROM表中的列,并将转换为 原生过滤器。WHERE子句还可以引用子查询,比如 WHERE col1 IN(SELECT foo FROM ...)。像这样的查询作为子查询的连接执行,如下在 查询转换 部分所述。
GROUP BY
GROUP BY子句引用FROM表中的列。使用 GROUP BY、DISTINCT 或任何聚合函数都将使用Druid的 三种原生聚合查询类型之一触发聚合查询。GROUP BY可以引用表达式或者select子句的序号位置(如 GROUP BY 2以按第二个选定列分组)。
GROUP BY子句还可以通过三种方式引用多个分组集。 最灵活的是 GROUP BY GROUPING SETS,例如 GROUP BY GROUPING SETS ( (country, city), () ), 该实例等价于一个 GROUP BY country, city 然后 GROUP BY ()。 对于GROUPING SETS,底层数据只扫描一次,从而提高了效率。其次,GROUP BY ROLLUP为每个级别的分组表达式计算一个分组集,例如 GROUP BY ROLLUP (country, city) 等价于 GROUP BY GROUPING SETS ( (country, city), (country), () ) ,将为每个country/city对生成分组行,以及每个country的小计和总计。最后,GROUP BY CUBE为每个分组表达式组合计算分组集,例如 GROUP BY CUBE (country, city) 等价于 GROUP BY GROUPING SETS ( (country, city), (country), (city), () )。对不适用于特定行的列进行分组将包含 NULL, 例如,当计算 GROUP BY GROUPING SETS ( (country, city), () ), 与()对应的总计行对于"country"和"city"列将为 NULL。
使用 GROUP BY GROUPING SETS, GROUP BY ROLLUP, 或者 GROUP BY CUBE时,请注意,可能不会按照在查询中指定分组集的顺序生成结果。如果需要按特定顺序生成结果,请使用ORDER BY子句。
HAVING
HAVING子句引用在执行GROUP BY之后出现的列,它可用于对分组表达式或聚合值进行筛选,它只能与GROUP BY一起使用。
ORDER BY
ORDER BY子句引用执行GROUP BY后出现的列。它可用于根据分组表达式或聚合值对结果进行排序。ORDER BY可以引用表达式或者select子句序号位置(例如 ORDER BY 2 根据第二个选定列进行排序)。对于非聚合查询,ORDER BY只能按 __time 排序。对于聚合查询,ORDER BY可以按任何列排序。
LIMIT
LIMIT子句可用于限制返回的行数。它可以用于任何查询类型。对于使用原生TopN查询类型(而不是原生GroupBy查询类型)运行的查询,它被下推到数据进程。未来的Druid版本也将支持使用原生GroupBy查询类型来降低限制。如果您注意到添加一个限制并不会对性能产生很大的影响,那么很可能Druid并没有降低查询的限制。
5.4.2 常用操作
查询所有:
SELECT * FROM "mslogs"
查询count列:
SELECT "count" FROM "mslogs"
查询前5条:
SELECT * FROM "mslogs" LIMIT 5
分组查询:
SELECT ip FROM "mslogs" GROUP BY ip
排序:
SELECT * FROM "mslogs" ORDER BY __time DESC
求和:
SELECT SUM("count") FROM "mslogs"
最大值:
SELECT MAX("count") FROM "mslogs"
平均值:
SELECT AVG("count") FROM "mslogs"
查询6年前的数据:
SELECT * FROM "wikiticker" WHERE "__time" >= CURRENT_TIMESTAMP - INTERVAL '6' YEAR
去除重复查询:
SELECT DISTINCT "count" FROM "mslogs"