io
- mysql doublewrite:
共享表空间(2M)+数据文件
脏页->redo log->doublewrite buffer->共享表空间->数据文件
IO读写原理
基础知识:
先强调一个基础知识:read系统调用,并不是把数据直接从物理设备,读数据到内存。write系统调用,也不是直接把数据,写入到物理设备。
read系统调用,是把数据从内核缓冲区复制到进程缓冲区;而write系统调用,是把数据从进程缓冲区复制到内核缓冲区。这个两个系统调用,都不负责数据在内核缓冲区和磁盘之间的交换。底层的读写交换,是由操作系统kernel内核完成的。内核缓冲区与进程缓冲区:
缓冲区的目的,是为了减少频繁的系统IO调用。大家都知道,系统调用需要保存之前的进程数据和状态等信息,而结束调用之后回来还需要恢复之前的信息,为了减少这种损耗时间、也损耗性能的系统调用,于是出现了缓冲区。
有了缓冲区,操作系统使用read函数把数据从内核缓冲区复制到进程缓冲区,write把数据从进程缓冲区复制到内核缓冲区中。等待缓冲区达到一定数量的时候,再进行IO的调用,提升性能。至于什么时候读取和存储则由内核来决定,用户程序不需要关心。
在linux系统中,系统内核也有个缓冲区叫做内核缓冲区。每个进程有自己独立的缓冲区,叫做进程缓冲区。
所以,用户程序的IO读写程序,大多数情况下,并没有进行实际的IO操作,而是在读写自己的进程缓冲区。网络流程
client <----> 网卡 <--(read/write)--> 内核缓冲区(内核空间) <--(read/write)--> 用户缓冲区(用户空间)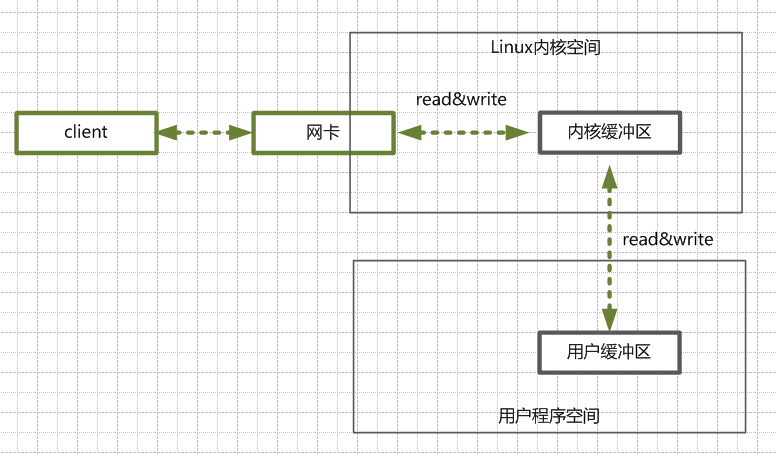
流程说明:
(1)客户端请求
Linux通过网卡,读取客户断的请求数据,将数据读取到内核缓冲区。
(2)获取请求数据
服务器从内核缓冲区读取数据到Java进程缓冲区。
(3)服务器端业务处理
Java服务端在自己的用户空间中,处理客户端的请求。
(4)服务器端返回数据
Java服务端已构建好的响应,从用户缓冲区写入系统缓冲区。
(5)发送给客户端
Linux内核通过网络 I/O ,将内核缓冲区中的数据,写入网卡,网卡通过底层的通讯协议,会将数据发送给目标客户端。同步异步&阻塞非阻塞:
阻塞IO:指的是需要内核IO操作彻底完成后,才返回到用户空间,执行用户的操作。阻塞指的是用户空间程序的执行状态,用户空间程序需等到IO操作彻底完成。传统的IO模型都是同步阻塞IO。在java中,默认创建的socket都是阻塞的。
同步IO:是一种用户空间与内核空间的调用发起方式。同步IO是指用户空间线程是主动发起IO请求的一方,内核空间是被动接受方。异步IO则反过来,是指内核kernel是主动发起IO请求的一方,用户线程是被动接受方。bio:
read调用[用户空间] --> (等待数据,比如接收完整socket包 --> 复制数据到用户缓冲区)[内核空间] --> 调用返回, 等待+复制都阻塞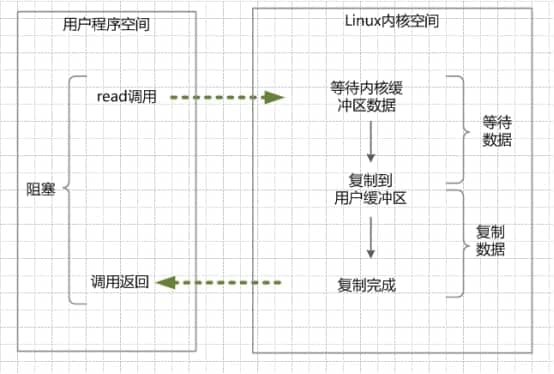
nio:
内核数据未准备好: read调用[用户空间] --> (立即返回)[内核空间] --> 不断轮询调用,直到数据准备好[用户空间]数据到达内核: read调用[用户空间] --> 阻塞(用户线程) --> 复制数据到用户缓冲区)[内核空间] --> 调用返回 复制数据阻塞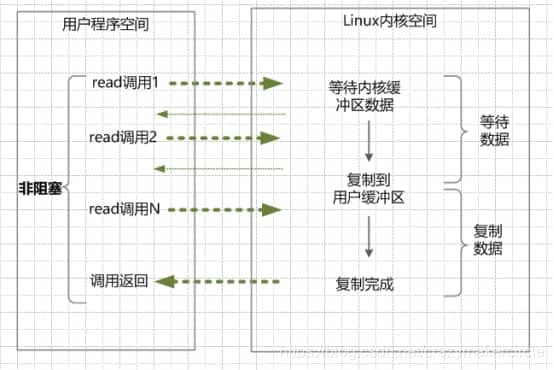
io多路复用:
通过一个进程监控多个文件描述符,一旦某个描述符就绪(一般是内核缓冲区可读/可写),就通知对应的程序进行IO调用
前提: 需要将目标网络连接,提前注册到select/epoll的可查询socket列表中。然后才可以开启整个的IO多路复用模型的读流程
select:
select调用 --> 查询所有可读连接 --> 返回连接给目标线程 --> 阻塞(用户线程) --> 复制数据 --> 调用返回, O(n)epoll:
epoll调用 --> 通知对应线程 --> 阻塞(用户线程) --> 复制数据 --> 调用返回, O(1)
aio:
read调用[用户空间] --> 不阻塞(用户线程) --> (等待数据 --> 复制数据)[内核空间] --> 发送信号或回调用户线程, 不阻塞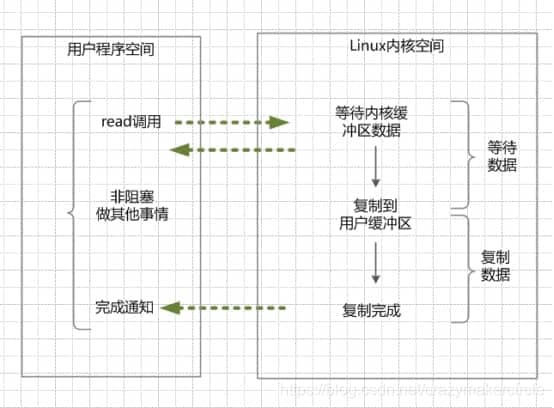
零拷贝
消息从发送到落地保存,broker维护的消息日志本身就是文件目录,每个文件都是二进制保存,生产者和消费者使用相同的格式来处理。在消费者获取消息时,服务器先从硬盘读取数据到内存,然后把内存中的数据原封不动的通过socket发送给消费者。虽然这个操作描述起来很简单,但实际上经历了很多步骤。
- 操作系统将数据从磁盘读入到内核空间的页缓存
- 应用程序将数据从内核空间读入到用户空间缓存中
- 应用程序将数据写回到内核空间到socket缓存中
- 操作系统将数据从socket缓冲区复制到网卡缓冲区,以便将数据经网络发出

通过“零拷贝”技术,可以去掉这些没必要的数据复制操作,同时也会减少上下文切换次数。现代的unix操作系统提供一个优化的代码路径,用于将数据从页缓存传输到socket;在Linux中,是通过sendfifile系统调用来完成的。Java提供了访问这个系统调用的方法:FileChannel.transferTo API
使用sendfifile,只需要一次拷贝就行,允许操作系统将数据直接从页缓存发送到网络上。所以在这个优化的路径中,只有最后一步将数据拷贝到网卡缓存中是需要的

页缓存
页缓存是操作系统实现的一种主要的磁盘缓存,但凡设计到缓存的,基本都是为了提升i/o性能,所以页缓存是用来减少磁盘I/O操作的。
磁盘高速缓存有两个重要因素:
- 第一,访问磁盘的速度要远低于访问内存的速度,若从处理器L1和L2高速缓存访问则速度更快。
- 第二,数据一旦被访问,就很有可能短时间内再次访问。正是由于基于访问内存比磁盘快的多,所以磁盘的内存缓存将给系统存储性能带来质的飞越。
当一个进程准备读取磁盘上的文件内容时, 操作系统会先查看待读取的数据所在的页(page)是否在页缓存(pagecache)中,如果存在(命中)则直接返回数据, 从而避免了对物理磁盘的I/0操作;如果没有命中, 则操作系统会向磁盘发起读取请求并将读取的数据页存入页缓存, 之后再将数据返回给进程。 同样,如果 一 个进程需要将数据写入磁盘, 那么操作系统也会检测数据对应的页是否在页缓存中,如果不存在, 则会先在页缓存中添加相应的页, 最后将数据写入对应的页。 被修改过后的页也就变成了脏页, 操作系统会在合适的时间把脏页中的数据写入磁盘, 以保持数据的 一 致性
Kafka中大量使用了页缓存, 这是Kafka实现高吞吐的重要因素之 一 。 虽然消息都是先被写入页缓存, 然后由操作系统负责具体的刷盘任务的, 但在Kafka中同样提供了同步刷盘及间断性强制刷盘(fsync), 可以通过 log.flush.interval.messages 和 log.flush.interval.ms 参数来控制。
同步刷盘能够保证消息的可靠性,避免因为宕机导致页缓存数据还未完成同步时造成的数据丢失。但是实际使用上,我们没必要去考虑这样的因素以及这种问题带来的损失,消息可靠性可以由多副本来解决,同步刷盘会带来性能的影响。 刷盘的操作由操作系统去完成即可