问题
1. java中是值传递还是引用传递?
- 基本数据类型和包装类,以及String类型都是值传递,对象类型是引用传递?
2. 子父类代码块执行顺序
子类和父类的静态代码块、构造代码块、构造方法的执行顺序
- 父静态代码块
- 子静态代码块
- 父构造代码块
- 父构造方法
- 子构造代码块
- 子构造方法
3. 哈希冲突解决方法
- 开放定址法
- 再哈希法
- 链地址法
- 建立公共溢出区
4. HashMap和HashTable的区别
- 两者父类不同
HashMap是继承自AbstractMap类,而Hashtable是继承自Dictionary类。不过它们都实现了同时实现了map、Cloneable(可复制)、Serializable(可序列化)这三个接口。 - 对外提供的接口不同
Hashtable比HashMap多提供了elments() 和contains() 两个方法。
elments() 方法继承自Hashtable的父类Dictionnary。elements() 方法用于返回此Hashtable中的 value的枚举。
contains()方法判断该Hashtable是否包含传入的value。它的作用与containsValue()一致。事实上, contansValue() 就只是调用了一下contains() 方法。 - 对null的支持不同
Hashtable:key和value都不能为null。
HashMap:key可以为null,但是这样的key只能有一个,因为必须保证key的唯一性;可以有多个key值对应的value为null。 - 安全性不同
HashMap是线程不安全的,在多线程并发的环境下,可能会产生死锁等问题,因此需要开发人员自己处理多线程的安全问题。
Hashtable是线程安全的,它的每个方法上都有synchronized 关键字,因此可直接用于多线程中。
虽然HashMap是线程不安全的,但是它的效率远远高于Hashtable,这样设计是合理的,因为大部分的使用场景都是单线程。当需要多线程操作的时候可以使用线程安全的ConcurrentHashMap。
ConcurrentHashMap虽然也是线程安全的,但是它的效率比Hashtable要高好多倍。因为 ConcurrentHashMap使用了分段锁,并不对整个数据进行锁定。 - 初始容量大小和每次扩充容量大小不同
- 计算hash值的方法不同
5. 锁优化策略
减少锁持有时间
只用在有线程安全要求的程序上加锁减小锁粒度
将大对象(这个对象可能会被很多线程访问),拆成小对象,大大增加并行度,降低锁竞争。 降低了锁的竞争,偏向锁,轻量级锁成功率才会提高。最最典型的减小锁粒度的案例就是 ConcurrentHashMap。锁分离
最常见的锁分离就是读写锁 ReadWriteLock,根据功能进行分离成读锁和写锁,这样读读不互 斥,读写互斥,写写互斥,即保证了线程安全,又提高了性能,具体也请查看[高并发 Java 五] JDK 并发包 1。读写分离思想可以延伸,只要操作互不影响,锁就可以分离。比如 LinkedBlockingQueue 从头部取出,从尾部放数据分段锁
在JDK8的CurrentHashMap、LongAdder中有此种实现
锁粗化
通常情况下,为了保证多线程间的有效并发,会要求每个线程持有锁的时间尽量短,即在使用完 公共资源后,应该立即释放锁。但是,凡事都有一个度, 如果对同一个锁不停的进行请求、同步和释放,其本身也会消耗系统宝贵的资源,反而不利于性能的优化 。锁消除
锁消除是在编译器级别的事情。 在即时编译器时,如果发现不可能被共享的对象,则可以消除这 些对象的锁操作,多数是因为程序员编码不规范引起。
参考: Java锁-导读
6. Java 线程池工作过程
- 线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面 有任务,线程池也不会马上执行它们。
- 当调用 execute() 方法添加一个任务时,线程池会做如下判断:
- a) 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
- b) 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列;
- c) 如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
- d) 如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会抛出异常 RejectExecutionException。
- 当一个线程完成任务时,它会从队列中取下一个任务来执行。
- 当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运 行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它 最终会收缩到 corePoolSize 的大小。
7. 双亲委派模型
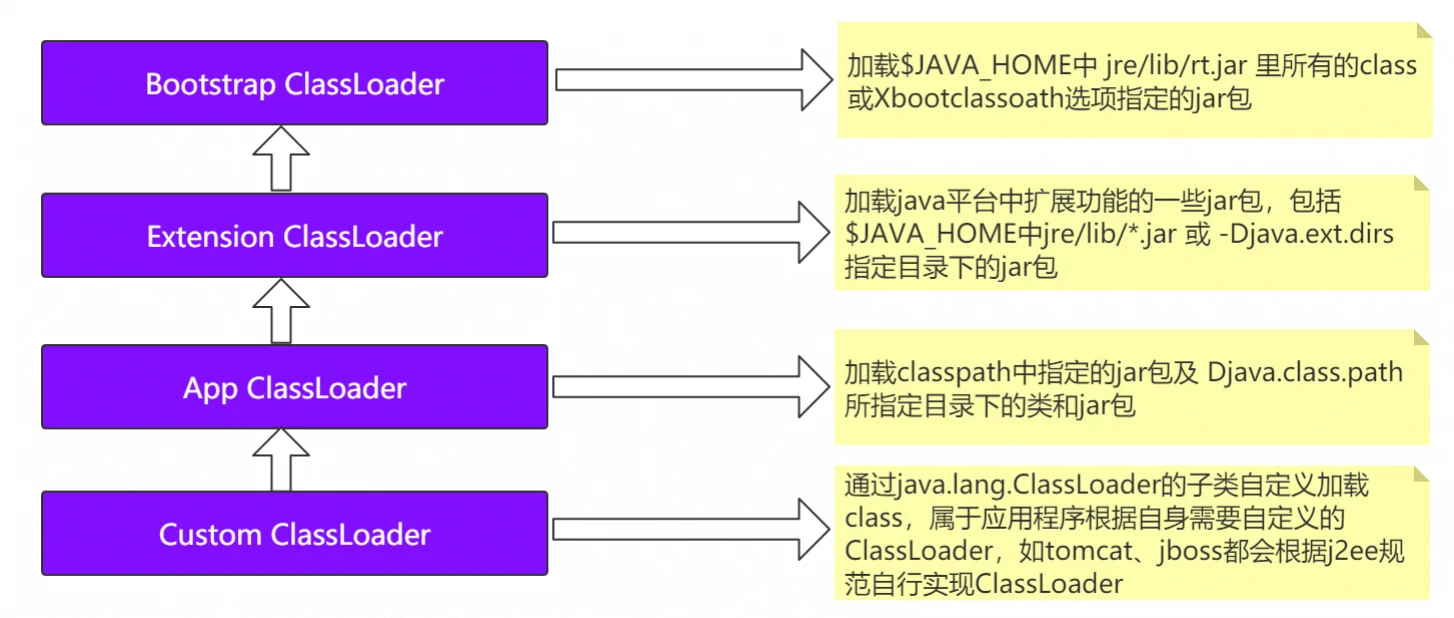
加载的顺序:加载的顺序是自顶向下,也就是由上层来逐层尝试加载此类。
双亲委派机制
定义:如果一个类加载器在接到加载类的请求时,它首先不会自己尝试去加载这个类,而是把这个请求任务委托给父类加载器去完成,依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。
优势:Java类随着加载它的类加载器一起具备了一种带有优先级的层次关系。比如,Java中的Object类,它存放在rt.jar之中,无论哪一个类加载器要加载这个类,最终都是委派给处于模型最顶端的启动类加载器进行加载,因此Object在各种类加载环境中都是同一个类。如果不采用双亲委派模型,那么由各个类加载器自己取加载的话,那么系统中会存在多种不同的Object类。
破坏:可以继承ClassLoader类,然后重写其中的loadClass方法,其他方式大家可以自己了解拓展一下。
8. 对象分配规则
- 对象优先分配在Eden区,如果Eden区没有足够的空间时,虚拟机执行一次Minor GC。
- 大对象直接进入老年代(大对象是指需要大量连续内存空间的对象)。这样做的目的是避免在Eden区和两个Survivor区之间发生大量的内存拷贝(新生代采用复制算法收集内存)。
- 长期存活的对象进入老年代。虚拟机为每个对象定义了一个年龄计数器,如果对象经过了1次Minor GC那么对象会进入Survivor区,之后每经过一次Minor GC那么对象的年龄加1,知道达到阀值对象进入老年区。
- 动态判断对象的年龄。如果Survivor区中相同年龄的所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象可以直接进入老年代。
- 空间分配担保。每次进行Minor GC时,JVM会计算Survivor区移至老年区的对象的平均大小,如果这个值大于老年区的剩余值大小则进行一次Full GC,如果小于检查HandlePromotionFailure设置,如果true则只进行Monitor GC,如果false则进行Full GC
9. 雪花算法
64bit = 1bit(0) + 41bit时间戳 + 10bit机器ID + 12bit序列号
- 1bit,不用,因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数,所以最高位固定为0。
- 41bit时间戳,毫秒级。可以表示的数值范围是 (2^41-1),转换成单位年则是69年。
- 10bit工作机器ID,用来表示工作机器的ID,包括5位datacenterId和5位workerId。
- 12bit序列号,用来记录同毫秒内产生的不同id,12位可以表示的最大整数为4095,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。
10. Autowired和Resource的区别
@Resource和@Autowired都是做bean的注入时使用,其实@Resource并不是Spring的注解,它的包是javax.annotation.Resource,需要 导入,但是Spring支持该注解的注入。
- 共同点
两者都可以写在字段和setter方法上。两者如果都写在字段上,那么就不需要再写setter方法。 - 不同点
@Autowired
@Autowired为Spring提供的注解,需要导入包org.springframework.beans.factory.annotation.Autowired;只按照byType注入public class TestServiceImpl { // 下面两种@Autowired只要使用一种即可 @Autowired private UserDao userDao; // 用于字段上 @Autowired public void setUserDao(UserDao userDao) { // 用于属性的方法上 this.userDao = userDao; } }@Autowired注解是按照类型(byType)装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它的required属 性为false。如果我们想使用按照名称(byName)来装配,可以结合@Qualifier注解一起使用。如下:
public class TestServiceImpl { @Autowired @Qualifier("userDao") private UserDao userDao; }@Resource
@Resource默认按照ByName自动注入,由J2EE提供,需要导入包javax.annotation.Resource。@Resource有两个重要的属性:name和 type,而Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。所以,如果使用name属性,则使 用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不制定name也不制定type属性,这时将通过反射机制 使用byName自动注入策略public class TestServiceImpl { // 下面两种@Resource只要使用一种即可 @Resource(name="userDao") private UserDao userDao; // 用于字段上 @Resource(name="userDao") public void setUserDao(UserDao userDao) { // 用于属性的setter方法上 this.userDao = userDao; } }注:最好是将@Resource放在setter方法上,因为这样更符合面向对象的思想,通过set、get去操作属 性,而不是直接去操作属性。
@Resource装配顺序:
- ①如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常。
- ②如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常。
- ③如果指定了type,则从上下文中找到类似匹配的唯一bean进行装配,找不到或是找到多个,都会抛出异常
- ④如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配。@Resource的作用相当于@Autowired,只不过@Autowired按照byType自动注入
11. ImportSelector和ImportBeanDefinitionRegistrar
ImportSelector -> selectImports
ImportBeanDefinitionRegistrar -> registerBeanDefinitions
12. Spring--Environment
13.
1