简历-s
约 6000 字大约 20 分钟
C2D3IJKM2N1R2S2Z
- Concurrent/Containerization+Dubbo/Distribute/Design+IO+Java+Kafka+Mybatis/MySQL+Network+Redis/RabbitMQ+Source/Spring+Zookeeper
ddfiwjjj:
- 多态+dubbo+分布式+io+微服务+架构+九大组件+Java对象
C2
并发编程(Concurrent)
基阻池安CA工(基础+阻塞队列+线程池+安全+CAS+AQS+工具/容器)
- 线程基础
- 区隔稳性粒
- 创TRC池C返抛
- 生NRBWTT(NEW RUNNABLE BLOCKED WAITING TIMED_WAITING TERMINATED)
- 方S3YJI3(start/stop/sleep+yield+join+interrupt/isInterrupted/interrupted)
- 阻塞队列
- 方抛返阻超 aopo+rptp+ep(插 add/offer/put/offer、删 remove/poll/take/poll、获 element/peek)
- 类ALDPS
- P锁满是fw否入es
- t锁空是ew否出fs
- 线程池
- 核核最时位阻场拒
- 状RSPDT(RUNNING/SHUTDOWN/STOP/TIDYING/TERMINATED)
- 流核任非拒(核心线程->任务队列->非核心线程->拒绝策略)
- 复WRHGTPK(Worker/runWorker/While/getTask/timed/poll?take)
- 关SNA(shutdown shutdownNow awaitTermination)
- 类C(Sc0)F(Lcm)G(Lcm1)S cached/fixed/single/scheduled
- 提SE参返异(submit/execute 区别: 参数+返回值+异常处理)
- 钩BAT(beforeExecute afterExecute terminated)
- 拒ADOCR(AbortPolicy/DiscardPolicy/DiscardOldestPolicy/CallerRunsPolicy/RejectedExecutionHandler)
- 好降响管数I2C1(好处:降低资源消耗+提高响应速度+提高线程的管理性, 线程数: IO密集=核心数*2 CPU密集=核心数+1)
- 线程安全
- 三原可序MESI
- 顺外传开教监
- S实静代(实例方法 静态方法 代码块)
- 头标元实齐,哈分同偏线(哈希+分代年龄+同步锁标记+偏向锁标记+偏向线程ID)
Java对象由三个部分组成:对象头、实例数据、对齐填充。
对象头由两部分组成,第一部分存储对象自身的运行时数据:哈希码、GC分代年龄、锁标识状态、线程持有的锁、偏向线程ID(一般占32/64 bit)。第二部分是指针类型,指向对象的类元数据类型(即对象代表哪个类)。如果是数组对象,则对象头中还有一部分用来记录数组长度。 - 升 无锁->偏向锁->轻量级锁->重量级锁
- AQS
- AswCSDP0(state: state=0-无锁,state>0多次获取了锁;waitStatus: CANCELLED(1)、SIGNAL(-1)、CONDITION(-2)、PROPAGATE(-3)、默认状态(0))
- 抢ataeasp(①acquire(arg)->②tryAcquire(arg)->③addWaiter->④自旋入队:enq->⑤自旋抢占: acquireQueued()->⑥shouldParkAfterFailedAcquire()->⑦parkAndCheckInterrupt())
- 放rtu(release()-> 钩子实现: tryRelease()-> 唤醒后继: unparkSuccessor())
- a封加释判是旋否阻(封装节点->加入WAIT队列->释放锁(完全)->判断是否在CLH队列:是->自旋获取锁,否->阻塞自己,等待被唤醒并加入CLH队列竞争锁)
- s判移加设换(判断是否持有锁->从WAIT队列移除当前头结点->加入到CLH队列->设置CLH原尾结点Signal失败->唤醒线程)
容器化(Containerization)
- DICVE: Docker,Image,Container,Volume,Engine
- C2ENTV: commit+copy, exec, network, tag, volume
- RIL2P3S4: run/rmi+image/ispect+logs/login, ps/pull/push, search/stats/start/stop
- FRLVC2E3AW: FROM,RUN,LABEL,Volume,COPY+CMD,ENV+ENTRYPOINT+EXPOSE,ADD,WORKDIR
- upisdel: up, ps, image, start, down, exec, logs
- PRDLSN: Pod->ReplicaSet->Deployment->Label->Service->Node
- MASDCEHWPL: api server+scheduler+dns+controller manager+etcd+dashboard, kube-proxy+kubelet
- AGCDS2: apply, get, config+create, describe+delete, scale+set
D3
Dubbo
- 协序注负容降
- 多协议: dubbo、rmi、hessian、http、webservice、thrift、rest
- 序列化: avro、fastjson、hessian、kryo、protobuf、protostuff、gson
- 多注册中心: consul、etcd、nacos、sofa、zookeeper、redis、multicast
- 负载均衡(权最一加): 权重随机、最少活跃、一致性hash、加权轮询
- 集群容错(OFSBKC): FailOver(切换)、FailFast(返回)、FailSafe(异常忽略)、FailBack(恢复)、Forking(并行调用,成一即回)、Broadcast(广播多个,任一报错则报错)
- 降级: mock降级,故障降级、限流降级
- 调用
- Cluster->Directory->Router->LoadBalance->Invoker
- exchange->transport->serialize
- scprcmpets
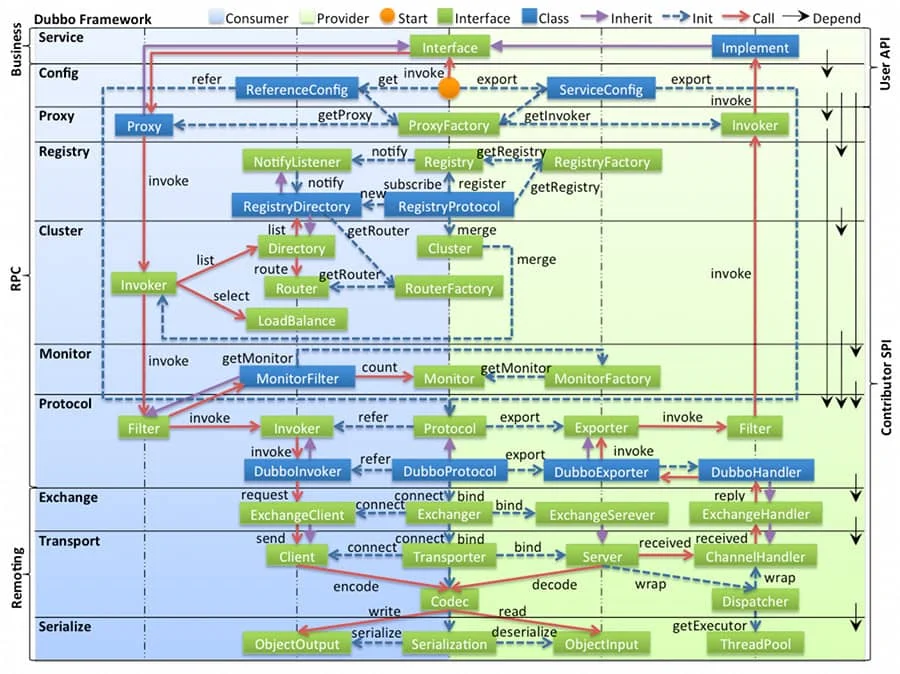
- 第一层:service层,接口层,给服务提供者和消费者来实现的
- 第二层:config层,配置层,主要是对dubbo进行各种配置的
- 第三层:proxy层,服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton
- 第四层:registry层,服务注册层,负责服务的注册与发现
- 第五层:cluster层,集群层,封装多个服务提供者的路由以及负载均衡,将多个实例组合成一个服务
- 第六层:monitor层,监控层,对rpc接口的调用次数和调用时间进行监控
- 第七层:protocol层,远程调用层,封装rpc调用
- 第八层:exchange层,信息交换层,封装请求响应模式,同步转异步
- 第九层:transport层,网络传输层,抽象mina和netty为统一接口
- 第十层:serialize层,数据序列化层。网络传输需要。
分布式(Distribute)
- 组件
- 通事锁缓消日搜配监会(通信、事物、锁、缓存、消息、日志、搜索、配置、监控、会话)
- 架构演变
- 单数集扩负读拆服
- 单数缓负分LD搜拆服线容云(单机、数据库分离、nginx负载、分库分表、LVS负载、DNS负载、搜索引擎、应用拆分、微服务、企业服务总线、容器化、云平台)
- 分布式事务
- 理论: CAPBASE
- 刚性: 强(一致性)低(并发)短(适合短事物)C(CP)阻(阻塞)低(效率低)分(不适合大型网站分布式)
- 类型: X(A)23(PC)JTAS(JTA/JTS)
- XA: atr(ap/tm/rm),a发(发起)t注打开(注册、打开、开始)A变(变更)t结准提关退(结束、准备、提交、关闭、退出)
- 2PC: 请(请求提交事物)询记响(询问、执行并记录日志、响应yes)提C2馈完(提交事务:发送commit请求+执行commit操作+反馈+Ack完成)回R2馈断(回滚事物:rollback请求+rollback操作+反馈+中断事物)
- 缺点: 性协致容(性能+协调者单点问题+丢失数据导致不一致+没有容错机制,全靠超时)
- 3PC: 1C询馈(canCommit:询问+反馈)2CP记回(预提交:PreCommit请求+执行事务并记录日志+ack回应)A断(中断:Abort请求+中断事物)3CD提馈完(执行提交:DoCommit请求+事物提交+反馈结果+完成事物)A滚馈断(中断:Abort请求+事物回滚+反馈结果+中断事物)
- 特点: 协参超 默提 N致(协调者和参与者都设置超时,2PC只有参与者超时机制,参与者无法收到协调者消息时默认commit,没有解决数据不一致问题)
- 使用少原因: 性数协维资(性能差+数据库XA协议不支持+协调者依赖独立J2EE中间件+运维复杂+不是所有资源都支持XA协议)
- 柔性: 弱(一致性)高(并发)长(适合长事物)A(AP)最(最终一致)中(中间状态)补(补偿接口)业(需要业务改造)
- 分类: 通异保最努补TCSA(通知型:异步确保+最大努力,补偿型:TCC+SAGA)
- 异保MQ: 半成执CR投本消轮保(发送方发送半消息+MQ返回成功+发送方执行事务+根据事务执行情况commit或rollback+如果rollback则丢弃消息,commit则投递给订阅方+订阅方执行本地事务+订阅方标记消息已消费+发送方执行本地事务出现问题,MQ会不断轮询事务状态,决定投递消息还是丢弃消息+订阅方消费成功由MQ保证)
- 异保本地表: A业消发回删B读返(事务A:写业务+写消息(二者在同一个本地事务)+发MQ消息+接收回执+改消息状态或删除,事务B:读消息写入数据+返回ack,如果中间失败需要重试或回滚,有定时任务扫描本地消息,事务B执行失败时需重试或通知A发送反消息)
- 最大努力通知型: 在异步确保型的基础上,订阅方操作由“订阅方执行本地事务”或“读消息写入数据”改为“调用通知服务”
设计思考(Design)
- 性能优化:
- 批异缓预池串索事结分锁: 批处理、异步处理、空间换时间(缓存)、预处理、池化思想、串行改并行、索引、避免大事务、优化程序结构(重复查询、多次创建)、深分页、锁粒度
- 锁优化:
- 持粒分段粗消C: 持有时间、减小锁粒度、锁分离(读写锁)、分段锁(CHM、LongAdder)、锁粗化、锁消除、CopyOnWrite
- 秒杀系统架构分析与实战
- Github-秒杀
- 冲负网U点
- 数查上库超秒
- 前页时拦站限询
- 服发预处接
- 数读可致扩
- 中间件
- 发存序跨确群,序事性靠协费

- 技术选型
- 需开成学开调流,扩安致维效稳技

I1
IO
- IO模型
- BR阻返 NRN非R阻返 IS阻可R阻返 AR非通
- BIO: R阻返: read调用->阻塞{等待数据+复制数据}(等待内核缓冲区数据->复制到用户缓冲区->复制完成)->调用返回
- NIO: RN非R阻返: read调用->立即返回->直到数据准备好(调用N次,过程非阻塞),read调用->阻塞[复制数据]->调用返回
- IO多路复用: S阻可R阻返: select调用->阻塞->等待可读连接,read调用->阻塞[复制数据]->调用返回
- AIO: R非通: read调用->非阻塞(做其他事情)->完成通知
- BR阻返 NRN非R阻返 IS阻可R阻返 AR非通
- IO性能技术
- 零拷贝
- 正常流程: 磁盘->内核空间缓存->用户空间缓存->socket缓冲区->网卡缓冲区
- 零拷贝: 磁盘->内核空间缓存->socket缓冲区->网卡缓冲区(减少从内核拷贝到用户缓存和从用户缓存拷贝到socket缓冲区)
- 页缓存
- 零拷贝
- Netty
- ncbs(NIO-channel/buffer/selector)
- buffer: 读原分片只接内(读写+原理+分配+分片+只读+直接+内存映射), c初p索lwcrp(capacity+position+limit)
- apfgrmscc(allocate+ put+ flip+ get+ rewind+ mark/reset+ clear+compact)
- IO模型: 阻非复信异
- Netty优点: 简(使用简单)功(功能强大: 编协序)扩(扩展性好)性(性能高)稳(成熟稳定)社(社区活跃)验(久经考验)
- BCEFHPB(Bootstrap+ Channel+ EventLoop+ ChannelFuture+ ChannelHandler+ ChannelPipeline+ ByteBuf)
- ByteBuf: 池效零切扩自索链(池化+减少了内存复制和GC,效率提升+零复制+不用切换读写模式+扩展性好+可自定义缓冲区+读写索引分开+链式调用)
- 粘包拆包: 流(因: '流'式协议)定(定长)分(分隔符)头体(消息头+消息体)应协(应用层协议)L(LineBased)D(Delimiter)F(FixedLength)编解(自定义编码接码器)
- 编解码: J(Java原生序列化缺点)跨(语言)大(码流大)性(性能低)XJHAKPT(第三方: xml+json+hessian+avro+kryo+protobuf)
- 序列化选型: 空(空间开销)性(性能)跨(跨语言/平台)扩(扩展性/兼容性)流(流行程度)学(学习难度)易(易用) XPJA
- 高性能: 非(非阻塞)零(零拷贝)池(内存池)R(Reactor线程模型:单多主从)锁(无锁化设计)并(高效并发)序(高性能序列化)参(灵活参数配置)
J1
Java
- 多态
- 变参左函静左,非静编左运右
- 成员变量(不管是否静态): 无论编译和运行,都参考左边(引用型变量所属的类)
- 成员函数:
- 静态成员函数: 无论编译和运行,都参考左边
- 非静态成员函数: 编译看左边,运行看右边
- 变参左函静左,非静编左运右
- ISO模型
- 应表会传网链物(应传网链4层)
- 物链网传会表应(反序)
- 设计原则
- 开单里依接合迪
- 设计模式
- 类型:
- 单工抽建原
- 适装桥组享代外
- 中访策备迭 观模命状职解
- 设计模式目的,让程序具有更好的:
- 代码重用性(相同功能代码,不用多次编写)
- 可读性(编程规范性)
- 可扩展性(增加新功能时十分方便)
- 可靠性(增加新功能后,对原来的功能没有影响)
- 实现高内聚,低耦合的特性
- 类型:
- JVM
- 装链初验准解
- MSNHR: method area、jvm stack、native method stack、heap、pc register
- OYESFT: old、young、eden、survivor、from、to
- 引可标复整代区
- SNPSOPOCG: serial、ParalNew(吞)、Parallel Scavenage、Serial Old(整)、Parallel Old(吞,整)、CMS(吞,清,初并重清)、G1(停,整,初并最筛)
- jpistm
- jcvamg: jconsole、jvisualvm、arthas、mat、gcviewer
- 垃圾回收过程
- 逃逸分析
- 向量自动化

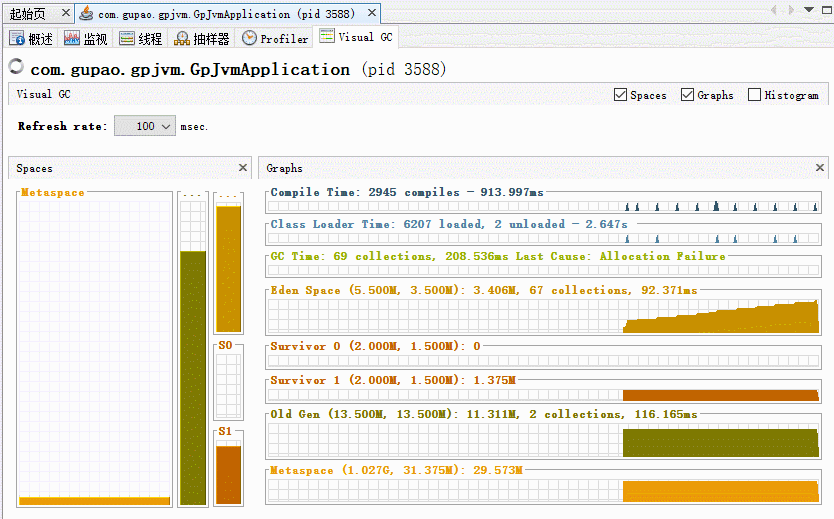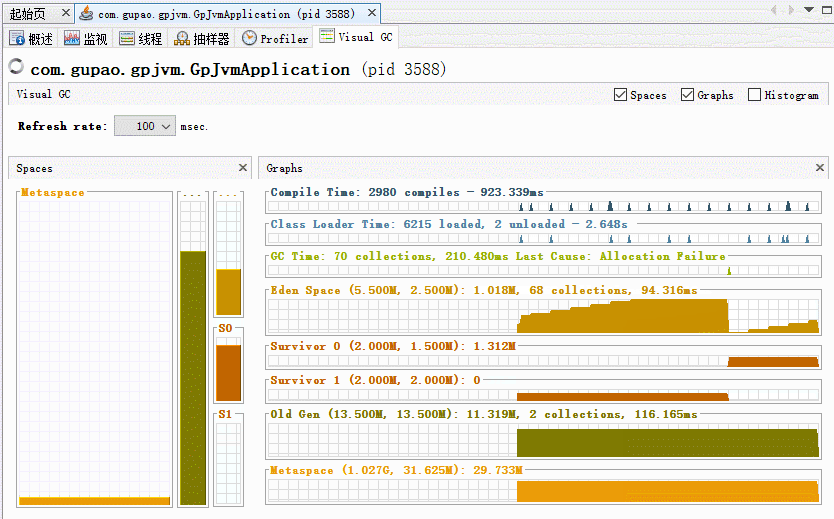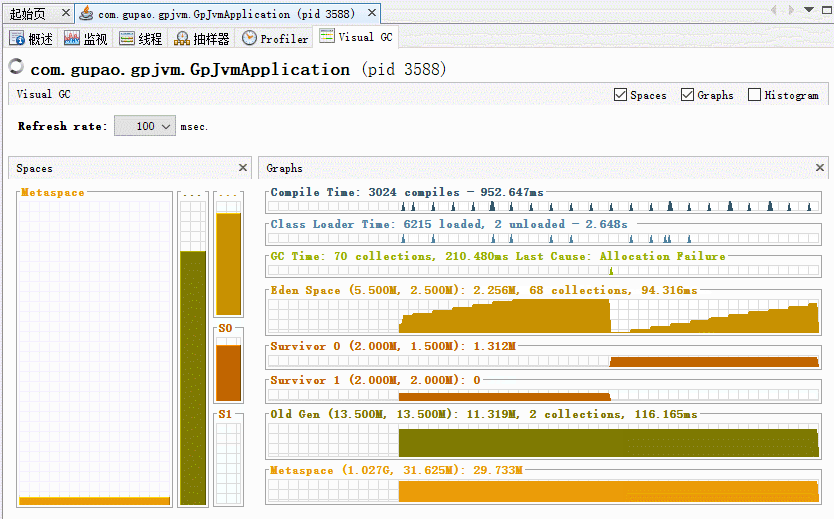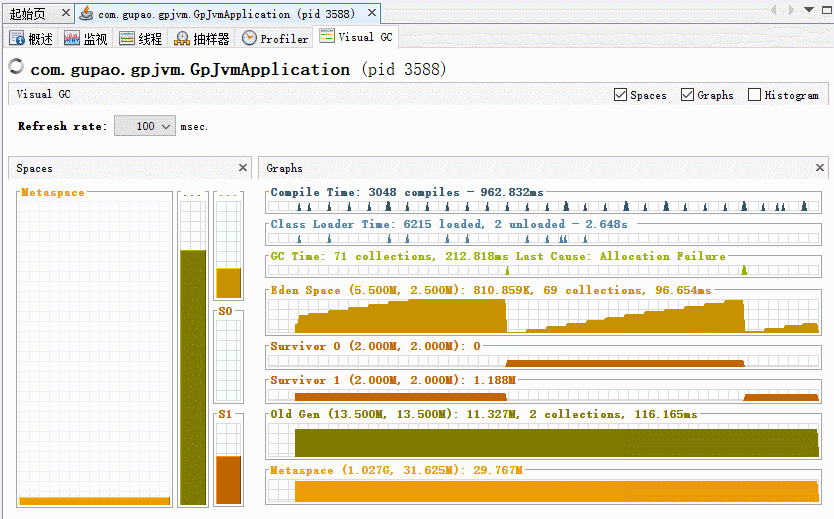
K1
Kafka
- 发送分区: partitioner接口自定义,默认hash取模
- 分范轮粘(消费分区):分区策略,范围、轮询、粘性
- ReJS:reBalance Join+Sync
- coordinator: 选择负载最小的broker节点
- join: consumer group 中所有成员向coordinator发送joinGroup请求,选举出leader(类似随机);确定分区策略,每个 consumer 将自己的分区策略发送到coordinator组成候选集,然后投票选出当前group的分区策略
- sync: 每个consumer向coordinator发送syncGroup请求,leader发送分配方案;coordinator把方案同步给所有consumer
- 可副AC

M3
MicroService
Mybatis
- 连S映动重缓插(特点)
- psaholem(properties、settings、typeAlies、typeHandlers、objectFactory、plugins、environment、mappers)
- 一BP二CM:多级缓存架构,(BaseExecutor->PretureCache SqlSession级别,CachingExecutor->Mapper级别)
- 核心对象:$\color{red}{CSESPRM2}$(Configuration、SqlSession、Executor、StatementHandler、ParameterHandler、ResultHandler、MapperProxy、MappedStatement)
- $\color{red}{micpmsleqfdghpqph}$
MySQL
- 三种SQL语言
- DDL(定义语言): 用于定义数据表的结构(如新增、删除、修改等) create/alert/drop table, create/drop index等;
- DML(操纵语言): 用于查询与修改数据记录 select, update, delete, insert;
- DCL(控制语言): 用来控制数据库的访问 grant, revoke, lock, rollback, commit, savepoint;
- 同异长短单半全: 同步长短半双工
- 查解处优划擎(cprole): 词解(单词)/语解(语法检查)-解析树,预处理器(表列别名等检查)-解析树
- 锁事存主聚行外查: ((行锁+表锁)&表锁、支持事务、ibd&(myi+myd)、主键、聚集索引、存储表的行数、支持外键、查询流程(回表&(先到myi查地址,再到myd查数据)))
- 连删解优查内改RBC: $\color{red}{WAL}$ 先写日志再写磁盘,写到redolog和内存就算更新完成了,异步更新磁盘
- 普唯全
- 存路扫读排稳: 分(二分)叉(二叉查找树)平(平衡二叉树)多(多路平衡查找树)B(B+树)
- 散左盖推创否: 创-wdnucfs(where+num+diff+update+composite+first+sort)
- 事擎特开并隔案: 幻读(插入),RR未解决幻读问题,MVCC无法读到新增(插入和删除版本号)
- 连架优存业
- 缓主从分用: 缓存、主从(单线程/异步/全同步/半同步/多库并行/GTID)、分库分表、高可用
- BLIRS: binlog->binlog dump thread->io thread->ready log->sql thread
- 设表字索编查重事索锁
- mysql事务失效的场景 存储引擎、非事务方法A调用事务B引起事务失效、like 查询用%开头引起的事务失效、mysql在使用不等于导致索引失效
- mysql索引失效的场景 联合索引不是最左匹配、使用了select *、索引列参与运算、索引列使用函数、错误like使用、隐式类型转换、使用or操作、两列做比较、不等于比较、is not null、not in和not exists、order 编译导致索引失效、参数不同导致索引失效、优化器发现走索引效率低
- mysql中in和or会走索引吗 in 不一定;or 不一定
N1
Network
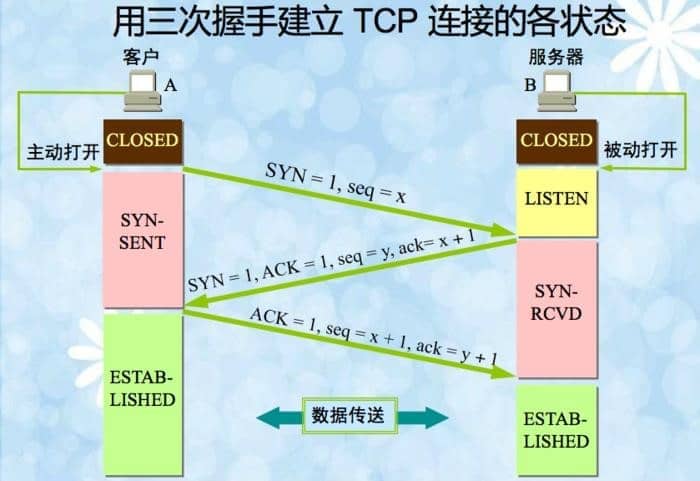
三次握手: yyAaAa
- y1qxSYN
- y1A1qyax1
- A1qx1ay1
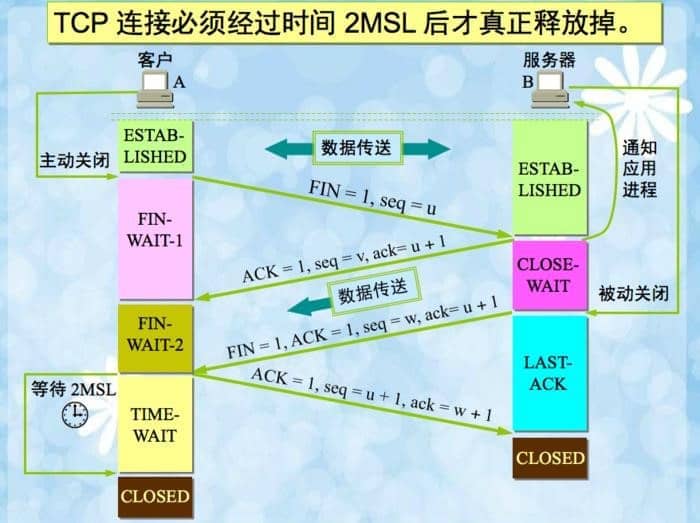
四次挥手: FAaFAaAa
- F1quFIN
- A1qvau1
- F1A1qwau1
- A1qu1aw1
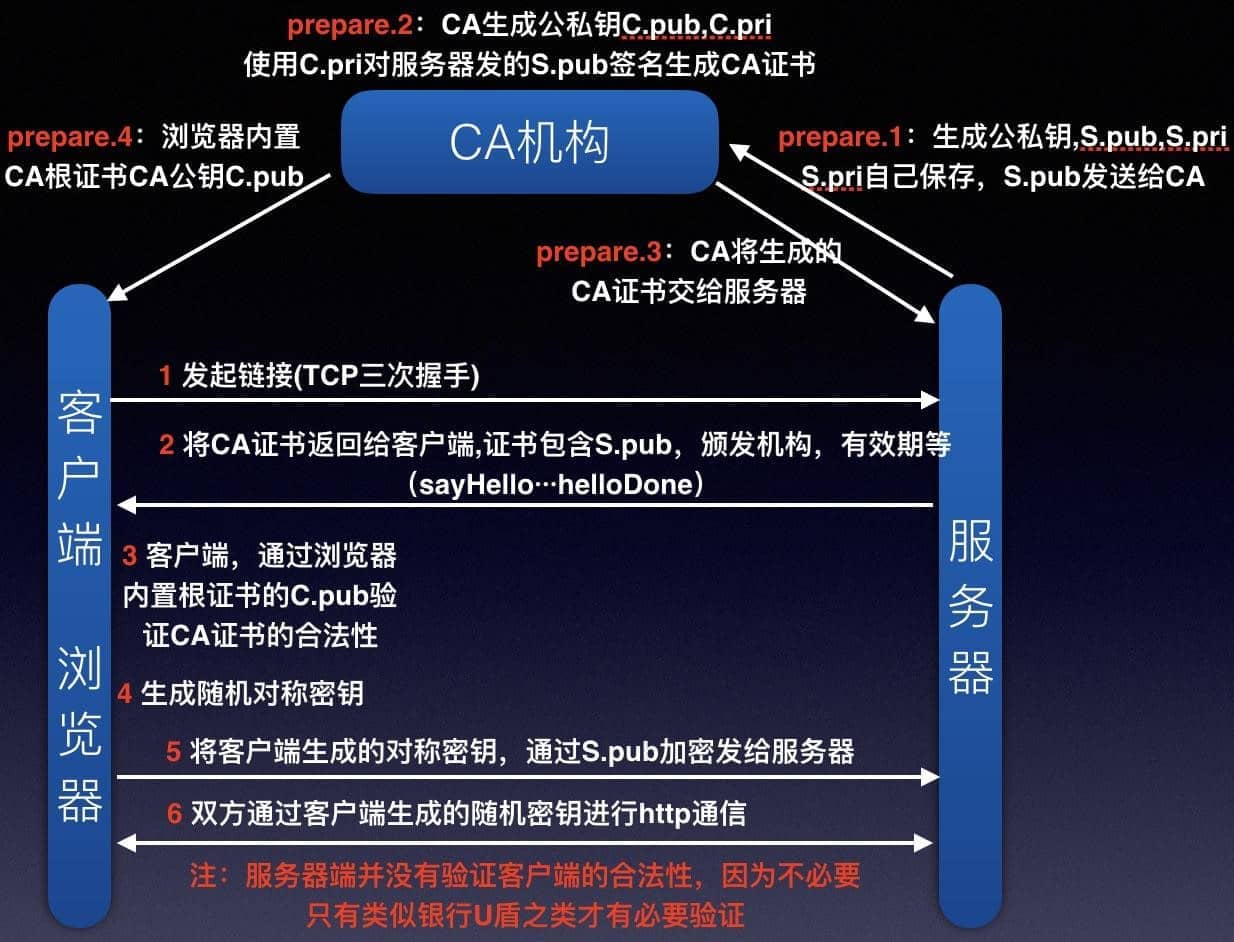
Https:
- 服生公私公发T(私保留)
- T签服公生CA(使用C.pri签名生成证书)
- CA发服流T公
- 连正验秘加解通

R2
RabbitMQ
- 异解削可复
- 靠路语扩用权插
- RVEQCH: broker, vhost, exchange, queue, connection, channel
- 直主#多*一广: direct, topic, fanout
- 过死延服三消P: 过期(队列+消息) + 死信(拒绝重回+过期+最大长度、设置dead-letter-exchange) + 延迟(定时+死信+delayed插件) + 服(参数+内存+磁盘) + 消(prefetch count)
- Cfamtlc: connectionfactory, admin, message, template, listener, converter
- Btc路回备: broker确认(transaction模式 + confirm模式(普通、批量、异步)) + 消息路由到队列(回发 + 备份交换机)
- 存队交消集:队列、交换机、消息持久化、集群
- 消费手自ack:消费确认,手动、自动ack
Redis
- 行结联语事扩改磁
- 存扩最高分
- 缓享锁主哈队
- $\color{red}{H购L时队S抽点筛Z排}$
- h购(物车)l时队(时间线、队列)s抽点筛(抽奖spop、点赞签到打卡sadd/srem/sismember/smembers、筛选: 差集-sdiff&交集-sinter&并集-sunion)z排(排行榜zincrby/zrevrange)
- 事MEDWL
- 过期策略: 定时过期 + 惰性过期
- 淘lrfurvae: volatile-lru/lfu/random、allkeys-lru/lfu/random、volatile-ttl、noeviction
- R规sfsb: rdb 规则(save 900 1)shutdown/flushall/save/bgsave
- 主从SenClu: 主从-rdb/指令/单点问题手动切换,sentinel-ping主观下线/超过半数-客观下线/单点写,cluster-一致性hash
- 断连优先复数id(sentinel)
- 先删后增延时双删
- $\color{red}{redis数据结构:}$
- 思ier([8,44], int/embstr/raw)
- 哈hz(数量<512&&长度都<64字节,hashtable+ziplist)
- 列q(quicklist=ziplist+linkedlist)
- 集hi(元素都是整数?intset:hashtable,数量>512->hashtable)
- 序sz(数量<128&&长度都<64字节,ziplist+skiplist)
- 击透崩:十分钟彻底掌握缓存击穿、缓存穿透、缓存雪崩
- 缓存击穿:一个并发访问量比较大的key在某个时间过期,导致所有的请求直接打在DB上(加锁更新、异步更新)
- 缓存穿透:缓存穿透指的查询缓存和数据库中都不存在的数据,这样每次请求直接打到数据库,就好像缓存不存在一样(缓存空值、布隆过滤器)
- 缓存雪崩:某⼀时刻⼤规模的缓存失效导致⼤量的请求进来直接打到DB上,可能使整个系统的崩溃,称为雪崩(热点不过期、均匀过期、集群部署、多级缓存、服务熔断、服务降级)
S2
Source
Spring
- 架构
- Joxst Boxe Apim & W3f (jdbc/orm/oxm/jms/transactions、beans/core/context/expression、aop/aspects/instrument/messaging、web/webmvc/websocket/webflux、test)
- 结构图

- beans
三大子类: ListableBeanFactory、AutowireCapableBeanFactory(getBean/createBean流程所在类)、HierarchicalBeanFactory
bean加载: BeanDefinition、BeanDefinitionReader
spring中controller是不是单例的?为什么?
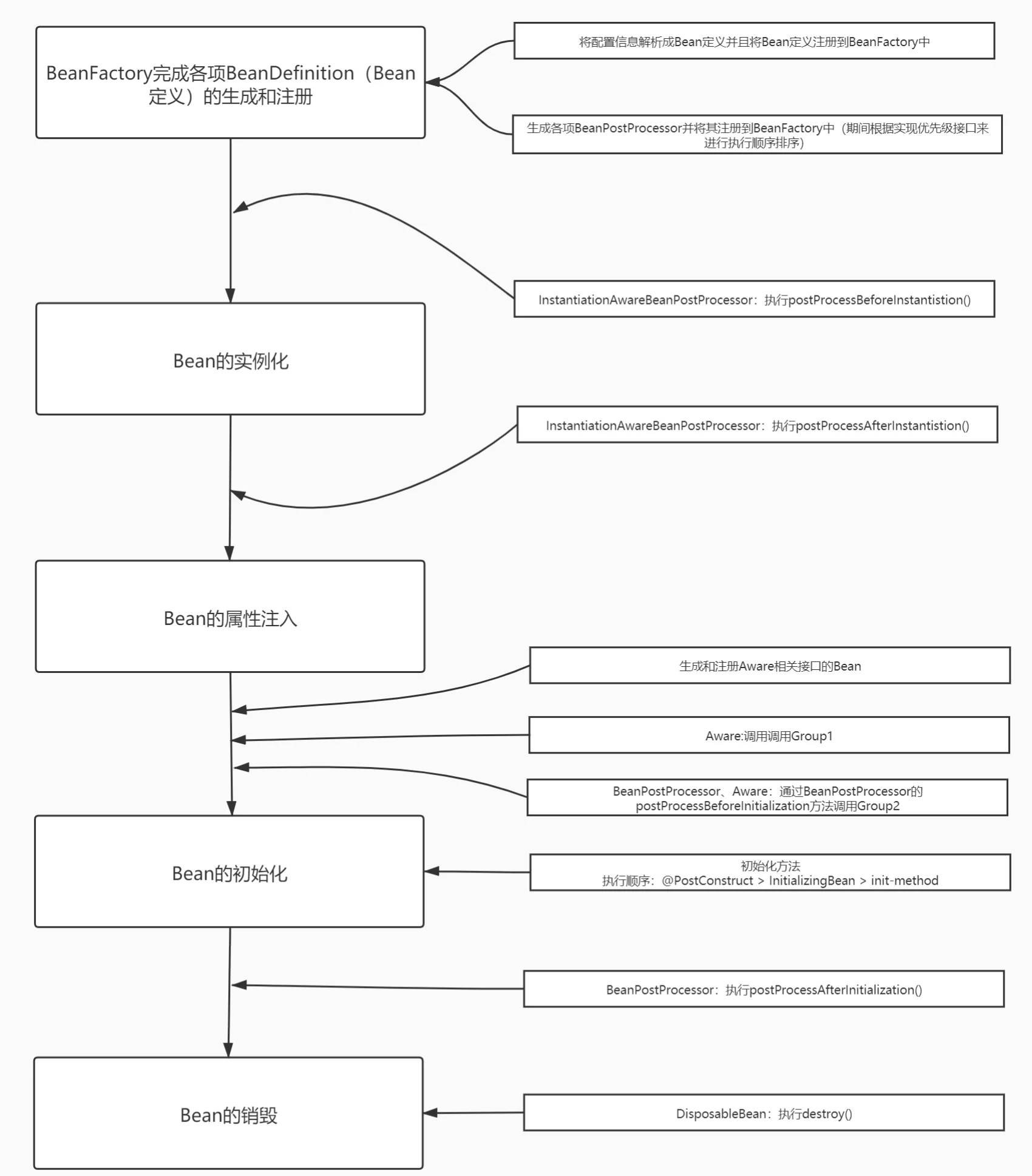
生命周期:
0. BeanDefinition- 实例化: InstantiationAwareBeanPostProcessor.postProcessBeforeInstantiation->createBeanInstance->InstantiationAwareBeanPostProcessor.postProcessAfterInstantiation
- 填充属性: populateBean
- 初始化: initializeBean->invokeAwareMethods(触发BeanNameAware/BeanClassLoaderAware/BeanFactoryAware)->BeanPostProcessor.postProcessBeforeInitialization->ApplicationContextAwareProcessor(触发EnvironmentAware/MessageSourceAware/ApplicationContextAware等)->InitializingBean->initMethod->BeanPostProcessor.postProcessAfterInitialization
- 销毁: DisposableBean->destroyMethod
- IBCFP,IIBAIIFDD
循环依赖:
- 一级缓存 singletonObjects(成品):
- 添加: addSingleton, 发生在 createBean 调用完成后的 getSingleton 调用中,同时移除二级和三级缓存;
- 移除: removeSingleton, 容器销毁时,移除 bean 实例;
- 二级缓存 earlySingletonObjects(半成品):
- 添加: getSingleton, 该方法被调用时,将 bean 从三级缓存移到二级缓存;
- 移除: addSingleton(addSingletonFactory/removeSingleton附带)
- 三级缓存 singletonFactories(原料):
- 添加: addSingletonFactory, 发生在 createBeanInstance 和 populateBean 之间
- 移除: getSingleton(addSingleton/removeSingleton附带)
- 整体流程
- 调用: getBean->doGetBean->createBean->(doCreateBean->createBeanInstance->addSingletonFactory->populateBean->initializeBean->getSingleton)->addSingleton
- 说明: 在 createBeanInstance 将 bean 加入三级缓存,并设置属性和初始化,当通过 getSingleton 获取的时候,将其从三级缓存移入二级缓存(一级和二级都未缓存该bean),整个 createBean 方法调用完成之后,会调用 addSingleton 方法将其从二级缓存移入一级缓存;再使用的时候,顺序相反,依次从一级、二级、三级缓存中进行获取,获取不到时才走下一级。
- 一级缓存 singletonObjects(成品):
- context核心: ApplicationContext
- ApplicationContext 对比 BeanFactory 增强点:
- MessageSource:支持信息源,可以实现国际化
- ResourcePatternResolver:访问资源
- ApplicationEventPublisher:支持应用事件
- ApplicationContext 对比 BeanFactory 增强点:
- aop
- 切通点对代,前后返还异
- 常用场景: 权限管理、日志记录、异常处理、事务处理、性能统计、安全控制、资源池管理
- mvc
- 九大组件: $\color{red}{上语模MAE预转F}$:上传、多语言、模板、HandlerMapping、HandlerAdapter、HandlerExceptionResolver、视图预处理、视图转换器、FlashMapManager
- 执行流程:

- 源码
$\color{red}{POPPIRMEOLFFDCR}$
$\color{red}{GDCDCAIPASS}$
$\color{red}{PIFAWGC}$
$\color{red}{MLTMAETVM + DPGHAHIPR}$ - 事务
- 61 张图,剖析 Spring 事务,就是要钻到底!
- 事务传播: 7种事务的传播机制(可通过spring配置或注解来设置)
$\color{red}{RSM4N}$- REQUIRED(默认):支持使用当前事务,如果当前事务不存在,创建一个新事务。
- SUPPORTS:支持使用当前事务,如果当前事务不存在,则不使用事务。
- MANDATORY:中文翻译为强制,支持使用当前事务,如果当前事务不存在,则抛出Exception。
- REQUIRES_NEW:创建一个新事务,如果当前事务存在,把当前事务挂起。
- NOT_SUPPORTED:无事务执行,如果当前事务存在,把当前事务挂起。
- NEVER:无事务执行,如果当前有事务则抛出Exception。
- NESTED:嵌套事务,如果当前事务存在,那么在嵌套的事务中执行。如果当前事务不存在,则表现跟REQUIRED一样。
- 事务并发
- 脏读: 一个事务读取到另一个事务未提交的数据,导致前后两次读取的数据不一致。
- 不可重复读:一个事务读取到了其他事务已提交的数据(修改或删除)导致前后两次读取数据不一致。
- 幻读:一个事务读取到了其他事务已提交的数据(新增)导致前后两次读取数据不一致。
- 事务失效
- spring 事务失效的 12 种场景 权限(非public)、final、方法内调用、未被spring管理、多线程调用、表不支持事务、错误传播机制、捕获了异常、手动抛异常、自定义异常、嵌套事务回滚
- security
- sss
- springboot admin
- hlbdmcse(health+loggers+beans+dump+mappings+conditions+shutdown+env)
- SpringCloud
- 配注熔调路消总负分(配置+注册/发现+熔断+调用+路由+消息+总线+负载均衡+分布式事务)
- 网关: 入路负限鉴监跨聚 入口、路由、负载、限流、鉴权、监控、跨域、聚合api文档
Z1
Zookeeper
- 2PC: 请询记响提
- 发负命协集选锁队
- 角节状版改权监
- (角色[leader/follower/observer]、节点[持久/临时/有序]、stat[c/m/pzxid+c/mtime+ac/version+dataLength+numChildren]、version[乐观锁]、增删改查[getData/create/setData/delete]、权限acl[ip/digest/world/super+create/read/write/delete/admin]、监听watcher[create/childrenChanged/dataChanged/deleted+pathChildCache/nodeCache/treeCache])
- 广播:zfacfc(zxid[leader生成zxid]+fifo[每个follower一个队列,放入proposal]+ack[follower记录proposal,回复ack]+commit[leader收到过半ack发送commit,同时在本地执行消息]+follower+commit[follower收到commit提交消息])
- 崩溃:两事要方(两件事[leader选举+数据同步] 两个要求[已处理的消息不能丢+已丢弃的消息不再出现] 两个要求应对方案[zxid最大者作为leader+zxid高低位(32位epoch+32位消息计数),每次选举epoch增加])
- QuorumCnxManager: MLSRsqlr (Message+Listener+SendWorker+RecvWorker+QuorumConnectionReqThread+QuorumConnectionReceiverThread
senderWorkerMap+queueSendMap+lastMessageSent+recvQueue) - FastLeaderElection: NTMW2sr(Notification+ToSend+Messenger+WorkerReceiver+WorkerSender sendqueue+recvqueue)
- 选举:投收处统状
- 每个 Server 发出一个投票。包含(myid, ZXID, epoch)
- 接受来自各个服务器的投票。判断该投票的有效性:是否本轮投票(epoch)、是否来自 LOOKING 状态的服务器
- 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行 PK,PK 规则如下:
- 优先比较 epoch,是否在同一周期内;
- 其次检查 ZXID。ZXID 比较大的服务器优先作为 Leader;
- 如果 ZXID 相同,那么就比较 myid。myid 较大的服务器作为Leader 服务器。
- 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息
- 改变服务器状态。Leader选出之后每个服务器变更自己的状态,Follower->FOLLOWING,Leader->LEADING。