问题-s
约 7323 字大约 24 分钟
- C2D3IJKM2N1R2S2Z
- Concurrent/Containerization+Dubbo/Distribute/Design+IO+Java+Kafka+Mybatis/MySQL+Network+Redis/RabbitMQ+Source/Spring+Zookeeper
- ddfiwjjj:
- 多态+dubbo+分布式+io+微服务+架构+九大组件+Java对象
C2
并发编程(Concurrent)
基阻池安CA工(基础+阻塞队列+线程池+安全+CAS+AQS+工具/容器)
- volatile是如何保证可见性和有序性
- lock指令+内存屏障
- 双重检查加锁单例模式为什么两次if判断
- 确保高并发模式下创建的是单例
- java中线程的生命周期
- NRBWTT
容器化(Containerization)
- Docker镜像大小优化
- 通过&&将多条命令组合执行
RUN apt update -y && apt install unzip -y && RUN apt install curl - 使用Docker Squash 减小镜像大小
docker-squash image:old -t image:new - 使用较小的基础镜像 如python:3.9-alpine
- 使用多阶段构建来减小大小
- 不安装不需要的推荐包
apt install unzip -y --no-install-recommends && apt install curl --no-install-recommends -y - 在 apt install 命令后添加
rm -rf /var/lib/apt/lists/* - 使用 .dockerignore 文件 不复制某些文件
- 在 RUN 之后放置 COPY, 在这种情况下 docker 将能够更好地使用缓存功能
- 安装后删除软件包
RUN curl "https://xxx.com/xxx-linux-x86_64.zip" -o "aaa.zip" && unzip aaa.zip && sudo ./aaa/install && rm aaa.zip - 使用 Docker 镜像缩容工具 Dive + fromlatest.io + Docker Slim
- 通过&&将多条命令组合执行
- Docker与虚拟机的区别
- 启动速度+性能损耗+系统利用率+隔离性+安全性+创建/删除速度+交付/部署速度+可管理性+可用性
- Dockerfile中CMD&RUN&ENTRYPOINT的区别
- RUN命令适用于在 docker build 构建docker镜像时执行的命令
- CMD命令是在 docker run 执行docker镜像构建容器时使用,可以动态的覆盖CMD执行的命令
- CMD命令是用于默认执行的,且如果写了多条CMD命令则只会执行最后一条,如果后续存在ENTRYPOINT命令,则CMD命令或被充当参数或者覆盖,ENTRYPOINT一般用于执行脚本
- Dockerfile中的COPY和ADD区别
- COPY命令将主机的文件复制到镜像内,如果目录不存在,会自动创建所需要的目录,注意只是复制,不会提取和解压
- ADD命令相对于COPY命令,可以解压缩文件并把它们添加到镜像中
- 简述Kubernetes的优势、适应场景及其特点?
- 优势:容器编排、轻量级、开源、弹性伸缩、负载均衡;
- 场景:快速部署应用、快速扩展应用、无缝对接新的应用功能、节省资源,优化硬件资源的使用;
- 特点:
- 可移植: 支持公有云、私有云、混合云、多重云(multi-cloud)、
- 可扩展: 模块化、插件化、可挂载、可组合、
- 自动化: 自动部署、自动重启、自动复制、自动伸缩/扩展;
D3
Dubbo
Dubbo 支持哪些协议,每种协议的应用场景、优缺点?
协议名程 传输 序列化 连接 使用场景 dubbo默认 mina、netty、grizzy dubbo、hessian2(默认) 、java、json dubbo缺省采用单一长连接和NIO异步通讯 1.传入传出参数数据包较小 2. 消费者比提供者多 3. 常规远程服务方法调用 4.不适合传送大数据量的服务,比如 文件、传视务 rmi Java RMI Java 标准序列化 连接个数: 多连接 连接方式: 短连接 传输协议: TCP/IP 传输方式: BIO 1.常规RFC调用 2.与原RMI客户端互操作 3.可传文件 4.不支持防火墙穿透 hessian Servlet容器 hessian二进制序列化 连接个数:多连接 连接方式: 短连接 传输协议: HTTP 1. 提供者比消费者多 2.可传文件 3.跨语言传输 http Servlet容器 表单序列化 连接个数:多连接 连接方式: 短连接 传输协议: HTTP 传输方式:同步传输 1.提供者多余消费者 2.数据包混合 webservice HTTP SOAP文件序列化 连接个数: 多连接 连接方式: 短连接 传输协议: HTTP 1.系统集成 2.跨语言调用 thrift thrift RPC基础上修改报文头 长连接、NIO异步传输 Dubbo的总体的调用过程
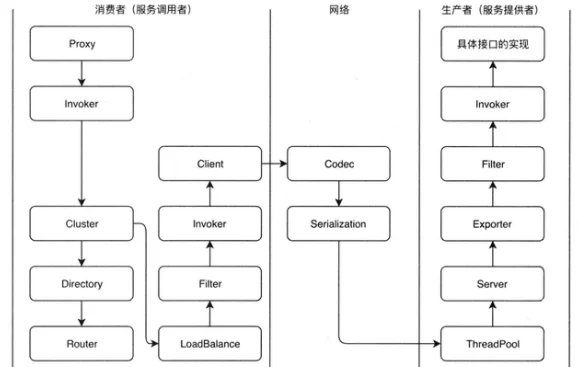
- Proxy持有一个Invoker对象,使用Invoker调用
- 之后通过Cluster进行负载容错,失败重试
- 调用Directory获取远程服务的Invoker列表
- 负载均衡用户配置了路由规则,则根据路由规则过滤获取到的Invoker列表用户没有配置路由规则或配置路由后还有很多节点,则使用LoadBalance方法做负载均衡,选用一个可以调用的Invoker
- 经过一个一个过滤器链,通常是处理上下文、限流、计数等。
- 会使用Client做数据传输
- 私有化协议的构造(Codec)
- 进行序列化
- 服务端收到这个Request请求,将其分配到ThreadPool中进行处理
- Server来处理这些Request
- 根据请求查找对应的Exporter
- 之后经过一个服务提供者端的过滤器链
- 然后找到接口实现并真正的调用,将请求结果返回
说说Dubbo的分层
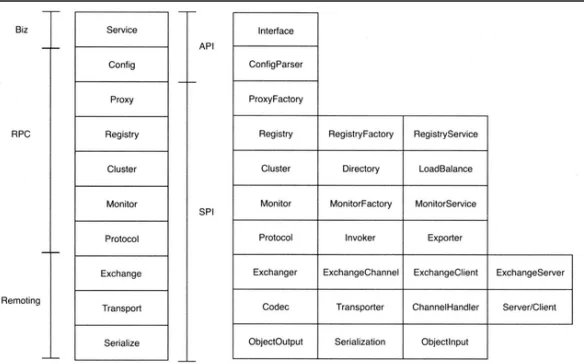
- 从大的范围来说,dubbo分为三层
- business业务逻辑层由我们自己来提供,接口和实现还有一些配置信息
- RPC层就是真正的RPC调用的核心层,封装整个RPC的调用过程、负载均衡、集群容错、代理
- remoting则是对网络传输协议和数据转换的封装。
- 从API、SPI角度来说,dubbo分为2层
- Service和Config两层可以认为是API层,主要提供给API使用者,使用者只需要配置和完成业务代码就可以了。
- 后面所有的层级是SPI层,主要提供给扩展者使用主要是用来做Dubbo的二次开发扩展功能。
- 再划分到更细的层面,就是图中的10层模式
- 从大的范围来说,dubbo分为三层
说说Dubbo的优先级配置(配置优先级别)
- 1.以timeout为例,显示了配置的查找顺序,其他retries,loadbalance等类似。
- 1)方法级优先,接口级次之,全局配置在次之
- 2)如果级别一样,则消费方优先,提供方次之
- 3)其中,服务提供方配置,通过URL经由注册中心传递给消费方
- 2.建议由服务提供方设置超时,因为一个方法需要执行多长时间,服务提供方更清楚,如果一个消费方同时引用多个服务,就不需要关心每个服务的超时设置。
- 1.以timeout为例,显示了配置的查找顺序,其他retries,loadbalance等类似。
Dubbo与SpringCloud的区别
- 初始定位不同:SpringCloud定位为微服务架构下的一站式解决方案;Dubbo 是 SOA 时代的产物,它的关注点主要在于服务的调用和治理
- 生态环境不同:SpringCloud依托于Spring平台,具备更加完善的生态体系;而Dubbo一开始只是做RPC远程调用,生态相对匮乏,现在逐渐丰富起来。
- 调用方式:SpringCloud是采用Http协议做远程调用,接口一般是Rest风格,比较灵活;Dubbo是采用Dubbo协议,接口一般是Java的Service接口,格式固定。但调用时采用Netty的NIO方式,性能较好。
- 组件差异比较多,例如SpringCloud注册中心一般用Eureka,而Dubbo用的是Zookeeper
分布式(Distribute)
- CAP理论理解
设计思考(Design)
I1
IO
Java NIO的缺陷
- NIO的类库和API繁杂,使用麻烦,你需要熟练掌握Selector、ServerSocketChannel、SocketChannel、ByteBuffer等
- 需要具备其它的额外技能做铺垫,例如熟悉Java多线程编程,因为NIO编程涉及到Reactor模式,你必须对多线程和网路编程非常熟悉,才能编写出高质量的NIO程序
- 可靠性能力补齐,开发工作量和难度都非常大。
例如客户端面临断连重连、网络闪断、半包读写、失败缓存、网络拥塞和异常码流的处理等等,NIO编程的特点是功能开发相对容易,但是可靠性能力补齐工作量和难度都非常大 - JDK NIO的BUG,例如臭名昭著的select bug,它会导致Selector空轮询,最终导致CPU 100%。
官方声称在JDK1.6版本的update18修复了该问题,但是直
Netty的特点
- 设计优雅 适用于各种传输类型的统一API - 阻塞和非阻塞Socket 基于灵活且可扩展的事件模型,可以清晰地分离关注点 高度可定制的线程模型 - 单线程,一个或多个线程池 真正的无连接数据报套接字支持(自3.1起)
- 高性能 、高吞吐、低延迟、低消耗
- 最小化不必要的内存复制
- 安全 完整的SSL / TLS和StartTLS支持
- 高并发:Netty 是一款基于 NIO(Nonblocking IO,非阻塞IO)开发的网络通信框架,对比于BIO(Blocking I/O,阻塞IO),他的并发性能得到了很大提高。
- 传输快:Netty 的传输依赖于零拷贝特性,尽量减少不必要的内存拷贝,实现了更高效率的传输。
- 封装好:Netty 封装了 NIO 操作的很多细节,提供了易于使用调用接口。
- 社区活跃,不断更新 社区活跃,版本迭代周期短,发现的BUG可以被及时修复,同时,更多的新功能会被加入
- 使用方便 详细记录的Javadoc,用户指南和示例 没有其他依赖项,JDK 5(Netty 3.x)或6(Netty4.x)就足够了
什么是Reactor线程模型
Netty如何解决JDK空轮询BUG
- 产生原因:
正常情况下,selector.select()操作是阻塞的,只有被监听的fd有读写操作时,才被唤醒。
但是,在这个bug中,没有任何fd有读写请求,但是select()操作依旧被唤醒很显然,这种情况下,selectedKeys()返回的是个空数组,然后按照逻辑执行到while(true)处,循环执行,导致死循环。 - 解决方案:
- 对Selector的select操作周期进行统计,每完成一次空的select操作进行一次计数。
- 若在某个周期内连续发生N次空轮询,则触发了epoll死循环bug。
- 重建Selector,判断是否是其他线程发起的重建请求,若不是则将原SocketChannel从旧的Selector上去除注册,重新注册到新的Selector上,并将原来的Selector关闭。
- 产生原因:
Netty如何实现断线重连
Netty如何实现心跳机制
J1
Java
聊聊:强引用、软引用、弱引用、虚引用? 重点说说,各自使用场景?
- 特点:
- 强引用(StrongReference)
一般new出来的对象就是强引用,即使在内存不足的情况下,JVM宁愿抛出OutOfMemory错误也不会随意回收这种对象。 - 软引用(SoftReference)
如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。 - 弱引用(WeakReference)
具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。 - 虚引用(PhantomReference)
如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。虚引用主要用来跟踪对象被垃圾回收器回收的活动。
- 强引用(StrongReference)
- 使用场景
- 强引用: 一般创建的对象都是强引用。
- 软引用: 在内存足够的情况下进行缓存,提升速度,内存不足时JVM自动回收;如caffeine源码。
- 弱引用: a. ThreadLocalMap防止内存泄漏 b. 监控对象是否将要被回收。
- 虚引用: 主要在 byteBuffer回收堆外内存(直接内存)的流程中。两种使用堆外内存的方法: 一种是依靠unsafe对象、另一种是NIO中的ByteBuffer
- 特点:
访问修饰符
private->default->protected->public: iftb 类(当前类)包(同包)子(子类)其(其他包)HashMap
- 为什么HashMap会产生死循环(出现在JDK7版本中)
- HashMap扩容时使用头插法 A->B->C 变成 C->B->A
- 并发环境下: T1 执行完之后的顺序是 B 到 A,而 T2 的顺序是 A 到 B,这样 A 节点和 B 节点就形成死循环了
- 解决方案: ConcurrentHashMap、Hashtable、synchronized 或 Lock 加锁
- HashMap除了死循环之外还有什么问题
- 数据覆盖、 无序性
- 为什么HashMap会产生死循环(出现在JDK7版本中)
设计模式
- 代码重用性(相同功能代码,不用多次编写)
- 可读性(编程规范性)
- 可扩展性(增加新功能时十分方便)
- 可靠性(增加新功能后,对原来的功能没有影响)
- 实现高内聚,低耦合的特性
JVM
K1
Kafka
M3
MicroService
- 微服务
Mybatis
- Mybatis延迟加载原理
- Mybatis仅支持association关联对象和collection关联集合对象的延迟加载
- 它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。
- Mybatis动态SQL
- 目的: 可以在 Xml 映射文件内,以标签的形式编写动态 sql,完成逻辑判断和动态拼接 sql 的功能
- 类型: trim|where|set|foreach|if|choose|when|otherwise|bind
- 原理: 使用 OGNL 从 sql 参数对象中计算表达式的值,根据表达式的值动态拼接 sql,以此来完成动态 sql 的功能
MySQL
N1
Network
R2
RabbitMQ
Redis
- 过期策略
- 定时过期(主动淘汰): 每个key设置一个过期时间,针对该key创建定时器检测,到期自动清除;
- 惰性过期(被动淘汰): 访问key时判断该key是否过期,过期则清除;
- 定期过期: 每隔一点时间,扫描一定数量的数据库的 expires 字典中一定数量的 key,并清除其中已过期的 key。
如果执行了过期策略,仍然没有回收到足够的内存空间,则需要执行淘汰机制。
- 淘汰策略
- lru-allkeys/volatile/random、lfu-allkeys/volatile/random、volatile-ttl、noeviction
- redis为什么块
- 完全基于内存操作
- 使⽤单线程,避免了线程切换和竞态产生的消耗
- 基于⾮阻塞的IO多路复⽤机制
- C语⾔实现,优化过的数据结构,基于⼏种基础的数据结构,redis做了⼤量的优化,性能极⾼
- redis6.0多线程
Redis 6.0中的多线程,也只是针对处理网络请求过程采用了多线程,而数据的读写命令,仍然是单线程处理的。 - redis10亿个可以,找出以固定前缀开头的10w个
keys指令(阻塞,服务停顿) -> scan指令(无阻塞的提取出指定模式的key列表,会有重复,需要手动去重,整体花费时间比keys长) - redis异步队列实现
- 用list结构作为队列,rpush生产消息,lpop消费消息;当lpop没有消息的时候,要适当sleep一会再重试;
- 不可以用sleep怎么做 -> list还有个指令叫blpop,在没有消息的时候,它会阻塞住直到消息到来;
- 能生产一次消费多次 -> 使用pub/sub主题订阅者模式,可以实现1:N的消息队列;
- pub/sub缺点 -> 在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如rabbitmq等;
- 如何实现延时队列 -> 使用sortedset,拿时间戳作为score,消息内容作为key调用zadd来生产消息,消费者用zrange by score指令获取N秒之前的数据轮询进行处理。
- redis持久化机制
rdb+aof - redis主从复制模式
- 配置: slaveof xxxx或者replicaof xxxx,断开 slave of no one
- 原理: 连接阶段(slave启动时根master建立连接,建立时间处理数据复制工作,并维持心跳) -> 数据同步阶段(全量复制, master通过bgsave生成rdb快照,slave清空自身数据然后从rdb快照加载) -> 命令传播阶段(增量复制, master异步复制给slave,通过 master_repl_offset 记录偏移量)
- 缺点: a.rdb文件过大则同步非常耗时 b.master宕机之后服务不可用,单点问题没解决,需要手动切换slave为master。
- redis sentinel
- 配置: 在
redis.conf配置 slaveof xxx, 同时配置sentinel.conf - 核心思想: 通过运行监控服务器来保证服务的可用性,Sentinel 既监控所有的 Redis 服务,Sentinel 之间也相互监控
- 服务下线:
- 主观下线: sentinel默认每隔1s向redis发送ping,如果在 down-after-milliseconds 时间内未收到回复,则将该服务标记为下线;
- 客观下线: Sentinel 节点会继续询问其他的 Sentinel 节点,确认服务是否下线,如果超过半数节点都认为此服务下线,才真正确认被下线
- 故障转移:
- 说明: 如果 master 被标记为下线,就会开始故障转移流程,需要进行leader选举
- slave升级为leader: 先发送 slaveof no one,然后向其他节点发送 slave of xxx(本机ip),让他们成为本机从节点
- 选举要素: 断开连接时长、优先级排序(越小优先级高)、复制数量(越多优先级高)、进程 id(越小优先级高)
- 功能: 监控、通知(实例故障,sentinel可以通过api通知)、自动故障转移(leader宕机可选出新leader)、配置管理(客户端连接sentinel获取redis地址)
- 缺点: a.主从切换会丢失数据,因为只有一个master b.只能单点写,没有解决水平扩容问题
- 配置: 在
- redis分布式
- 客户端Sharding: ShardJedis,不能实现动态服务增减,每个客户端需要维护分片策略
- 代理Proxy: Codis(豌豆荚)、Twemproxy
- RedisCluster:
- 数据分布: 一致性hash, 对 key 用 CRC16 算法计算再 %16384,得到一个 slot 的值,数据落到负责这个 slot 的 Redis 节点上
- 集群选举原理:
- slave发现自己的master变为FAIL
- 将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST 信息
- 其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack
- 尝试failover的slave收集master返回的FAILOVER_AUTH_ACK
- slave收到超过半数master的ack后变成新Master(这里解释了集群为什么至少需要三个主节点,如果只有两个,当其中一个挂了,只剩一个主节点是不能选举成功的)
- slave广播Pong消息通知其他集群节点。
- redis优化
- 尽量使用短的key
- 不要存过大的数据
- 避免使用keys *
- 在存到Redis之前先把你的数据压缩下
- 设置key有效期
- 选择回收策略(maxmemory-policy)
- 减少不必要的连接(使用连接池)
- 限制redis的内存大小
- 使用pipline批量操作数据
- 选择合适的数据结构
- 大key问题
- 大key会造成什么问题呢?
- 客户端耗时增加,甚至超时
- 对大key进行IO操作时,会严重占用带宽和CPU
- 造成Redis集群中数据倾斜
- 主动删除、被动删除等,可能会导致阻塞
- 如何找到大key?
- bigkeys 命令:使用bigkeys命令以遍历的方式分析Redis实例中的所有Key,并返回整体统计信息与每个数据类型中Top1的大Key
- redis-rdb-tools:redis-rdb-tools是由Python写的用来分析Redis的rdb快照文件用的工具,它可以把rdb快照文件生成json文件或者生成报表用来分析Redis的使用详情。
- 如何处理大key?
- 删除大key
- 当Redis版本大于4.0时,可使用UNLINK命令安全地删除大Key,该命令能够以非阻塞的方式,逐步地清理传入的Key。
- 当Redis版本小于4.0时,避免使用阻塞式命令KEYS,而是建议通过SCAN命令执行增量迭代扫描key,然后判断进行删除。
- 压缩和拆分key
- 当vaule是string时,比较难拆分,则使用序列化、压缩算法将key的大小控制在合理范围内,但是序列化和反序列化都会带来更多时间上的消耗。
- 当value是string,压缩之后仍然是大key,则需要进行拆分,一个大key分为不同的部分,记录每个部分的key,使用multiget等操作实现事务读取。
- 当value是list/set等集合类型时,根据预估的数据规模来进行分片,不同的元素计算后分到不同的片。
- 删除大key
- 大key会造成什么问题呢?
- 击透崩:十分钟彻底掌握缓存击穿、缓存穿透、缓存雪崩
- 缓存击穿:一个并发访问量比较大的key在某个时间过期,导致所有的请求直接打在DB上(加锁更新、异步更新)
- 缓存穿透:缓存穿透指的查询缓存和数据库中都不存在的数据,这样每次请求直接打到数据库,就好像缓存不存在一样(缓存空值、布隆过滤器)
- 缓存雪崩:某⼀时刻⼤规模的缓存失效导致⼤量的请求进来直接打到DB上,可能使整个系统的崩溃,称为雪崩(热点不过期、均匀过期、集群部署、多级缓存、服务熔断、服务降级)
- redis分布式锁
- 分布式锁特点:
- 互斥性: 在同一时刻只能有一个线程持有锁。
- 可重入性: 同一节点上的同一个线程如果获取了锁之后能够再次获取锁。
- 锁超时:和J.U.C中的锁一样支持锁超时,防止死锁
- 高性能和高可用: 加锁和解锁需要高效,同时也需要保证高可用,防止分布式锁失效
- 解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
- 常见分布式锁实现方案:
- 数据库悲观锁;
- 数据库乐观锁;
- 基于Redis的分布式锁;
- 基于ZooKeeper的分布式锁。
- redission锁
- 存储: hash结构,key为锁的名称(如lock-order)、field为UUID+threadId、value是重入次数(首次加锁为1)
- 加锁逻辑: lua脚本 1.exists判断key是否存在,不存在就 hset+pexpire; 2.hexists判断key和field是否存在,存在就hincrby(加1)+pexpire; 3.返回剩余过期时间。
- 解锁逻辑: lua脚本 1.hexists判断key和field是否存在,不存在返回nil; 2.hincrby减1返回counter; 3.counter>0, pexpire设置过期时间; 4.count<=0, del删除锁+publish(广播0到channel,通知等待线程获取锁) 5.counter为空,返回nil。
- watchdog续期: 加锁成功后开启守护线程,默认有效期是30秒,每隔10秒就会给锁续期到30秒,如果宕机了自然就在有效期失效后自动解锁。
- 要使 watchLog机制生效 ,lock时不要设置过期时间,watchdog 会每 lockWatchdogTimeout/3 时间去延时,lockWatchdogTimeout不要设置太小。
- redis主从切换数据未复制导致锁丢失: Redisson RedLock(不只在一个redis实例上创建锁,应该是在多个redis实例上创建锁,n/2 + 1,必须在大多数redis节点上都成功创建锁,才能算这个整体的RedLock加锁成功)
- 分布式锁特点:
S2
Source
Spring
beans
- spring中controller是不是单例的?
- 默认是单例的
- spring bean的生命周期?
- IBCFP,IIBAIIFDD
- spring解决循环依赖?
- addSingleton -> getSingleton -> addSingletonFactory
- spring中的单例bean是线程安全的吗
- 不是 spring没有做线程安全方面的限制
- spring中controller是不是单例的?
context核心:
aop
- 常用场景:
- 权限管理、日志记录、异常处理、事务处理、性能统计、安全控制、资源池管理
- spring aop和aspectj aop区别?
- 1)AspectJ是静态代理的增强,所谓静态代理,就是AOP框架会在编译阶段生成AOP代理类,因此也称为编译时增强,他会在编译阶段将AspectJ(切面)织入到Java字节码中,运行的时候就是增强之后的AOP对象。
- 2)Spring AOP使用的动态代理,所谓的动态代理就是说AOP框架不会去修改字节码,而是每次运行时在内存中临时为方法生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法
- 常用场景:
mvc
事务
- spring事务失效场景
- 权限(非public)、final、方法内调用、未被spring管理、多线程调用、表不支持事务、错误传播机制、捕获了异常、手动抛异常、自定义异常、嵌套事务回滚
- spring事务失效场景
security
- sss
springboot
优点
- 快速构建项目
- 嵌入式Web容器
- 易于构建任何应用
- 使用starter简化maven依赖
- 自动化配置
- 开发者工具
- 强大的应用监控
- 默认提供测试框架
- 可执行Jar部署
- 对主流开发框架的无配置集成
- 极大地提高了开发、部署效率
配置加载顺序(profile解析顺序)
- 开发者工具 Devtools 全局配置参数;
- 单元测试上的
@TestPropertySource注解指定的参数; - 单元测试上的
@SpringBootTest注解指定的参数; - 命令行指定的参数,如 java -jar springboot.jar --name="Java技术栈" ;
- 命令行中的 SPRING_APPLICATION_JSON 指定参数, 如 java -Dspring.application.json='{"name":"Java技术栈"}' -jar springboot.jar
- ServletConfig 初始化参数;
- ServletContext 初始化参数;
- JNDI参数(如 java:comp/env/spring.application.json );
- Java系统参数(来源: System.getProperties() );
- 操作系统环境变量参数;
- RandomValuePropertySource 随机数,仅匹配: ramdom.* ;
- JAR包外面的配置文件参数( application-{profile}.properties(YAML) )
- JAR包里面的配置文件参数( application-{profile}.properties(YAML) )
- JAR包外面的配置文件参数( application.properties(YAML) )
- JAR包里面的配置文件参数( application.properties(YAML) )
- `@Configuration 配置文件上 [ @PropertySource](mailto: @PropertySource) 注解加载的参数;
- 默认参数(通过 SpringApplication.setDefaultProperties 指定);
数字小的优先级越高,即数字小的会覆盖数字大的参数值
hlbdmcse(health+loggers+beans+dump+mappings+conditions+shutdown+env)
SpringCloud
- 配注熔调路消总负分(配置+注册/发现+熔断+调用+路由+消息+总线+负载均衡+分布式事务)
- 网关: 入路负限鉴监跨聚 入口、路由、负载、限流、鉴权、监控、跨域、聚合api文档
Z1
Zookeeper
参考
- Java
- MySQL
- Redis
- Spring
- Docker
- Mybatis
- Netty